
From: https://getboulder.com/boulder-artist-rocks-the-world/
Overview
Notice: The original article come from https://blog.mygraphql.com/en/posts/cloud/istio/istio-tunning/istio-thread-balance/ . If picture unclear, please redirect to the original article.
There is Chinese version too.
For a long time, programmers relied on Moore’s Law. And before it hits the ground, programmers find another lifesaver: parallelism/concurrency/eventual consistency. Today, Cloud Native/Micro-Service everywhere. Multi-threading by default. In the world of computer performance engineering, there is also a word: Mechanical Sympathy. The requirement of “Sympathy” is to understand how it work. In daily life, many people understand and pursue work life balance. But your thread, is it balance? Do you want to sympathize with it? What kind of sympathy is a thread that is tired enough to be overloaded and sees other companions eating afternoon tea? How can I get multithreading to maximum throughput?
Getting Started
My project has always been concerned about service latency. The introduction of Istio has significantly increased service latency, and how to minimize latency has always been the focus of performance tuning.
Testing Environment
Istio: v10.0 / Envoy v1.18
Linux Kernel: 5.3
Invocation topology:
(Client Pod) --> (Server Pod)
Client Pod includes:
Cient(40 threads) --> Envoy(2 worker threads by default)
Server Pod includes:
Envoy(2 worker threads by default) --> Server
Client/Serve is Fortio ( an Istio performance testing tool ) . The protocol of traffic is HTTP/1.1 keepalive.
Performance Issue
During the Performance test, it was found that the TPS could not increase with the number of client concurrent, and the overall CPU utilization of Client/Server/envoy was not high.
First of all, I am concerned about whether there is a bottleneck on the sidecar.
Envoy Worker load not balance
Envoy worker thread utilization
Because Envoy is a CPU-sensitive app. At the same time, the core architecture is an event-driven, non-blocking thread group. So observing the situation of the thread can usually find important clues:
|
|
According to the Envoy threading model (https://blog.envoyproxy.io/envoy-threading-model-a8d44b922310). Connections are bound on threads, and all requests on connections are handled by the bound thread. This binding is determined when the connection is established and does not change until the connection is closed. Therefore, busy threads are likely to bind a relatively large number of connections.
🤔 Why bind connection to thread?
Inside Envoy, connections are stateful data, especially for HTTP connections. In order to reduce lock contention for shared data between threads, and also to improve the hit rate of CPU caches, Envoy adopts this binding design.
Envoy connection distribution to worker
Envoy provides a large number of monitoring statistics: https://www.envoyproxy.io/docs/envoy/latest/configuration/upstream/cluster_manager/cluster_stats. First, open it using Istio’s method:
|
|
Getting Envoy stats:
|
|
It can be seen that the distribution of connections is quite uneven. In fact, the Envoy community on Github has already complained:
- Investigate worker connection accept balance (https://github.com/envoyproxy/envoy/issues/4602#issuecomment-544704931)
- Allow REUSEPORT for listener sockets https://github.com/envoyproxy/envoy/issues/8794
At the same time, the solution is also given: SO_REUSEPORT .
The solution
What is SO_REUSEPORT
A relatively original and authoritative introduction: https://lwn.net/Articles/542629/
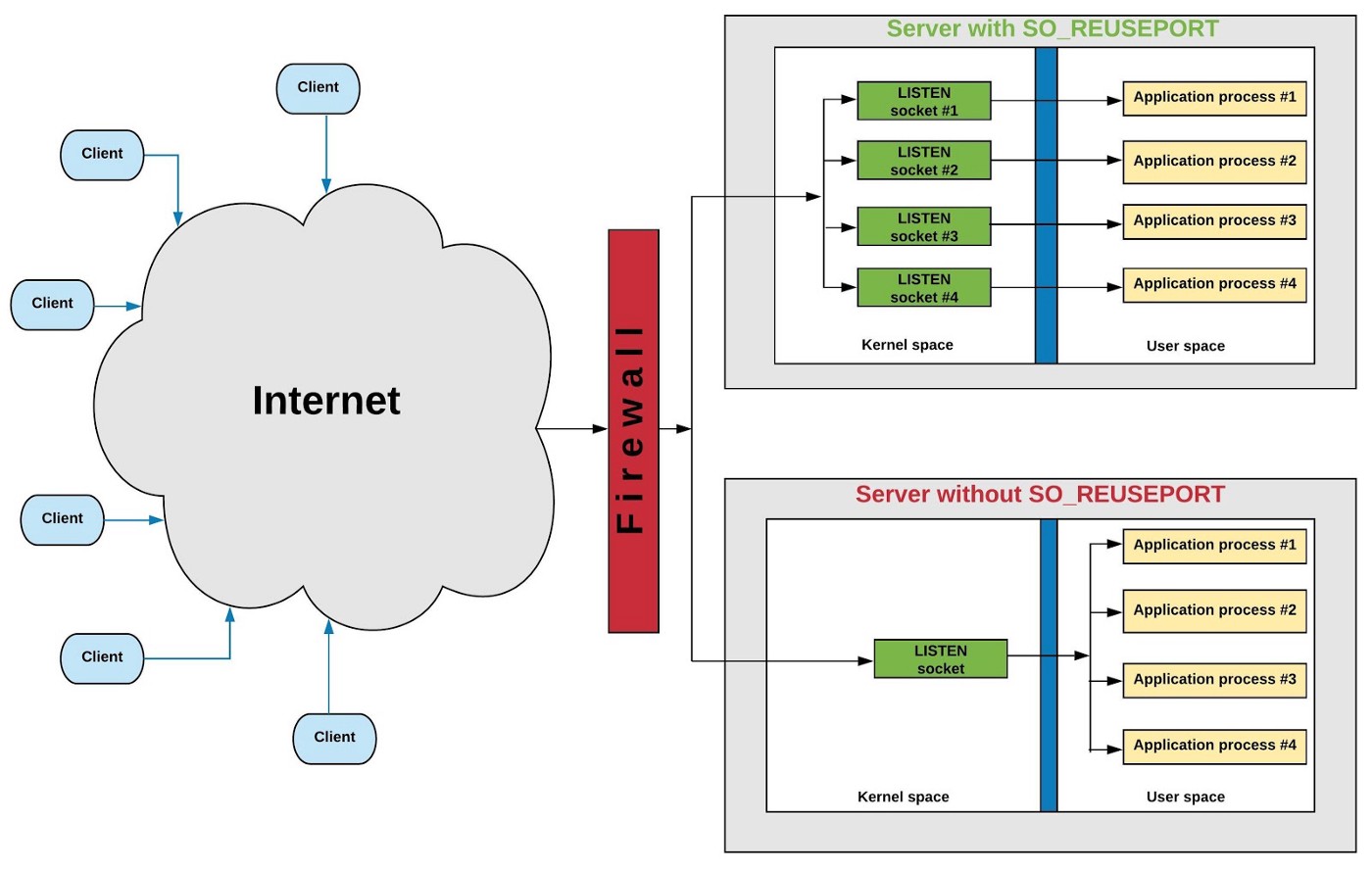
from: https://tech.flipkart.com/linux-tcp-so-reuseport-usage-and-implementation-6bfbf642885a
In a nutshell, multiple server sockets listen on the same port. Each server socket corresponds to a listening thread. When the kernel TCP stack receives a client connection request (SYN), according to the TCP 4-tuple (srcIP, srcPort, destIP, destPort) hash algorithm, select a listening thread, and wake it up. The new connection is bound to the thread that is woken up. So connections are more evenly distributed across threads than non-SO_REUSEPORT (the hash algorithm is not absolutely average).
Envoy Listner SO_REUSEPORT Configuration
Envoy named the component that listens and receives connections as Listener. There are two kinds of listeners when Envoys acting as a sidecar:
- virtual-Listener, with the name ‘virtual’, but, this is actually listener for the socket. 🤣
- virtual-outbound-Listener: Outbound traffic. Listen on port 15001. External requests made by the application running on the same POD as sidecar are redirected to this listener by
iptableand forwarded by Envoy. - virtual-inbound-Listener: Inbound traffic. Listen on port 15006. Receives traffic from other PODs.
- virtual-outbound-Listener: Outbound traffic. Listen on port 15001. External requests made by the application running on the same POD as sidecar are redirected to this listener by
- non-virtual-outbound-Listener, Every port of each k8s service corresponds to a
non-virtual-outbound-Listenernamed0.0.0.0_$PORT. This Listener does not listen on ports.
Detail: https://zhaohuabing.com/post/2018-09-25-istio-traffic-management-impl-intro/#virtual-listener
Back to the main point of this article, we only concerned with the Listener that actually listens to the socket, that is, virtual-Listener. The goal is to have it use SO_REUSEPORT so that new connections are more evenly distributed among threads.
In Envoy v1.18, there is a Listener parameter:reuse_port:
https://www.envoyproxy.io/docs/envoy/v1.18.3/api-v3/config/listener/v3/listener.proto
reuse_port (bool) When this flag is set to true, listeners set the SO_REUSEPORT socket option and create one socket for each worker thread. This makes inbound connections distribute among worker threads roughly evenly in cases where there are a high number of connections. When this flag is set to false, all worker threads share one socket. Before Linux v4.19-rc1, new TCP connections may be rejected during hot restart (see 3rd paragraph in ‘soreuseport’ commit message). This issue was fixed by tcp: Avoid TCP syncookie rejected by SO_REUSEPORT socket.
In Envoy v1.18 which I use, it is FALSE by default. In the latest version (v1.20.0, which was not released at the time of writing), this switch has been changed and is turned on by default:
https://www.envoyproxy.io/docs/envoy/latest/api-v3/config/listener/v3/listener.proto
reuse_port (bool) Deprecated. Use enable_reuse_port instead. enable_reuse_port (BoolValue) When this flag is set to true, listeners set the SO_REUSEPORT socket option and create one socket for each worker thread. This makes inbound connections distribute among worker threads roughly evenly in cases where there are a high number of connections. When this flag is set to false, all worker threads share one socket. This field defaults to true. On Linux, reuse_port is respected for both TCP and UDP listeners. It also works correctly with hot restart.
✨ Digression: If you need to distribute connections absolutely equally, you can try Listener’s configuration
connection_balance_config: exact_balance, I haven’t tried it, but because of the lock, there should be a certain performance loss for high-frequency new connections.
Well, the remaining question is how to open the reuse_port. Let’s take virtualOutbound as an example:
|
|
Yes, the POD needs to be restarted.
I’ve always felt that one of the biggest problems with Cloud Native is that you modify a configuration and it’s hard to know if it’s actually take effect. The design principles for target state configuration are certainly good, but the reality is that visibleability cannot keep up. So, let’s double check it:
|
|
Luckily, it took effect * (the reality is, due to environmental problems, I tossed a day 🤦 for this to take effect)*:
|
|
If you’re an obsessive-compulsive disorder person like me, take a look at the list of listening sockets:
|
|
Yes, both sockets are listening on the same port. Linux once again broke our stereotypical thinking and proved once again that it was a monster penguin.
Tuning Results
The load of the threads is relatively average:
|
|
The connections are more evenly distributed between the two threads:
|
|
The TPS of the service has also improved.
Lessons learned
I don’t really like to write summaries, and I think saving the lessons learned may be more useful. Open Source/Cloud Native has evolved to this day, and I feel more and more like a search/stackoverflow/github/yaml engineer. Because almost all requirements have opensource component availability, solving a simple problem probably only needs:
- Clearly define the keyword of the problem.
- Search keyword, which filters information that you think is important based on experience.
- Browse the relevant Blog/Issue/Documentation/Source code.
- Think about filtering information.
- Take actions and experiments.
- Goto 1.
- If none of the above steps work, create a Github Issue. Of course, fixing yourself as a contributor is perfect.
I don’t know if that’s a good thing or a bad thing. search/stackoverflow/github makes people feel that searching is learning, and finally knowledge becomes fragmented mechanical memory, lacking systematic cognition that has been deeply dive and examined by oneself, far from thinking and innovation.
About sequels
In the next part, I’m going to see how to use CPU binding, memory binding, HugePages, and optimization of Istio/Envoy under the NUMA hardware architecture. Of course, it is also Based on Kubernetes’ ‘Topology Management’ and ‘CPU/MemoryManager’. Until now, the temporary effect has not been great, nor has it been very smooth. There is a lot of information on the Internet about the cost of optimizing the Envoy stack with eBPF, but I think it is not technically mature and I have not seen the ideal cost effect.
Reference
Istio:
SO_REUSEPROT:
- https://lwn.net/Articles/542629/
- https://tech.flipkart.com/linux-tcp-so-reuseport-usage-and-implementation-6bfbf642885a
- https://www.nginx.com/blog/socket-sharding-nginx-release-1-9-1/
- https://domsch.com/linux/lpc2010/Scaling_techniques_for_servers_with_high_connection%20rates.pdf
- https://blog.cloudflare.com/perfect-locality-and-three-epic-systemtap-scripts/
- https://lwn.net/Articles/853637/