Introduction
Adding a chatbot to a blog is both interesting and practical. It can answer readers’ simple questions based on the blog content and the author’s introduction articles. ChatBlog (chat + blog) might be an engaging and useful model for interactive technical sharing. This article documents my exploration and implementation process.
Currently, the interactive knowledge base + LLM model is popular. A blog serves as an open knowledge base for tech enthusiasts, and making it open to chat is an intriguing idea.
Motivation

If you want to learn a new technology, what’s the best way to stay interested and get started quickly? My answer is to apply it in real-world scenarios, making it valuable and keeping the motivation for learning. This has always been my approach. In this article, I will share my attempt at building a personal AI career representative using RAG, LangChain, and Ollama (this sentence was auto-completed by Copilot as I typed it—quite ironic, isn’t it?).
Since the code for this project is quite messy, I don’t plan to open-source it. Instead, I will focus on the design concepts.
Goal
Integrate the AI career representative into my blog, allowing those interested in my professional background or technical experience to interact using a more modern chat-based method beyond just browsing the blog.
Data Sources
What knowledge should an AI career representative have? It is similar to the content classification of most technical blogs. First, it must know the “personal resume” of the individual it represents, followed by technical experience outputs (blog articles). In theory, feeding this data as a corpus to an LLM should suffice to create a career representative AI. The personal resume is a Markdown file, and the blog consists of multiple Markdown files organized in a directory structure.
Reality Check
- I don’t know how to fine-tune an LLM, so my toolbox is limited to RAG & Prompt Engineering.
- As a 24/7 service, I don’t want to keep my self-hosted machine running all the time, nor do I want to rent a VPS. I plan to solve this with an On-Demand boot (starting the machine and service upon request).
- Public web access to a self-hosted computer is a challenge. A direct public IP is never a good idea; alternative methods are needed.
- The server hardware is a 4-core machine without a GPU, which means response times will be in minutes rather than seconds. There’s no easy fix for this.
Design
Deployment
If an interviewer asks whether high-level design, logical design, or physical deployment design should come first, the textbook answer is “high-level design.” However, in the self-hosted world, everything must be considered together due to limited design space. To achieve a functional application within these constraints, patterns must be broken. Therefore, I start with physical deployment.

-
Initialize the blog content vector database.
-
A user accesses the chatbot embedded in an iframe within the blog, routing through Cloudflare to an Envoy proxy on a Raspberry Pi.
- Envoy requests the startup page from the Nginx upstream.
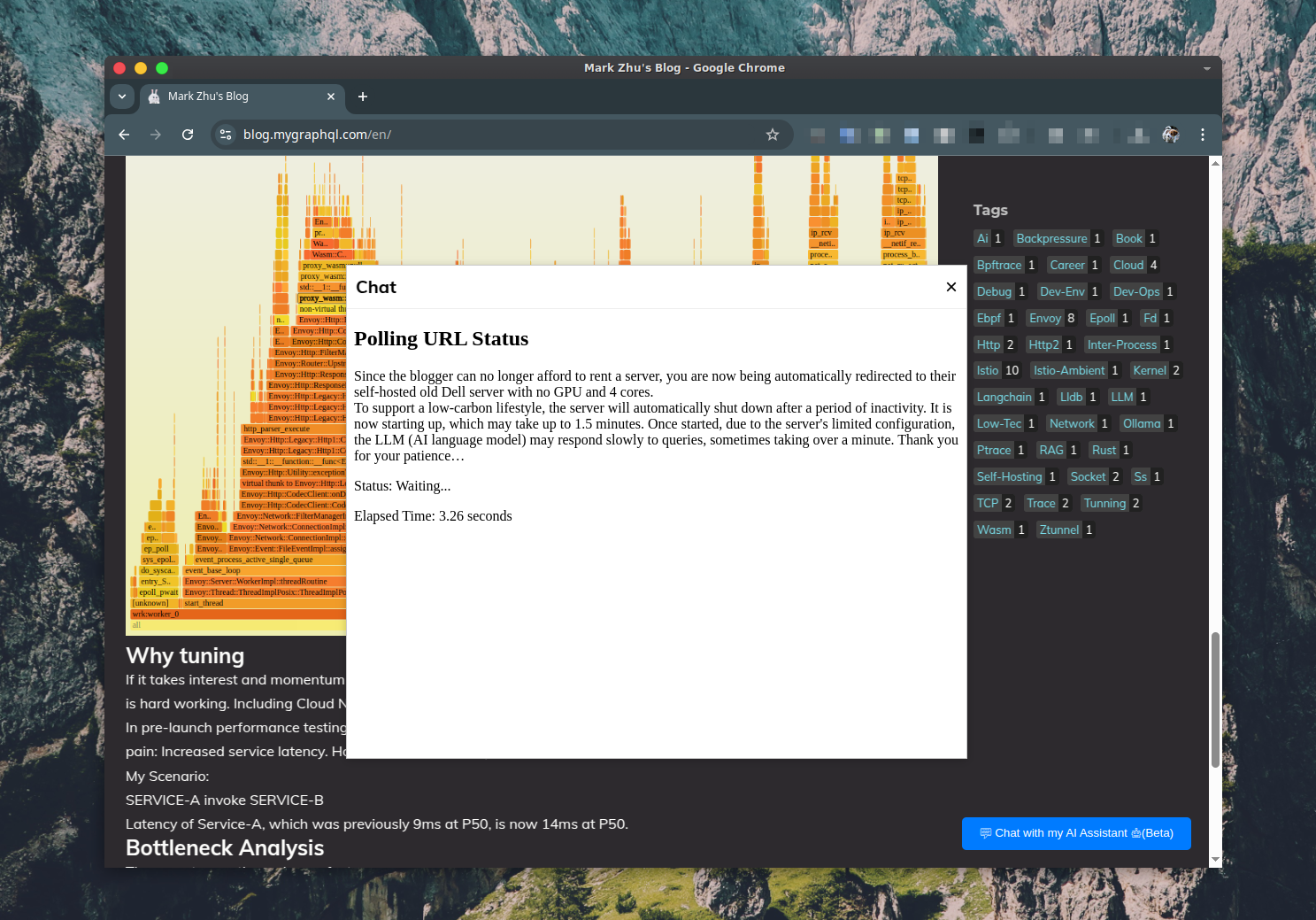
- The startup page HTML contains JavaScript polling another Envoy-reverse-proxied webhook for
server health waitingservice. - The webhook calls a Bash script, which checks if the target server is off and, if so, starts it using Wake-on-LAN.
- The Bash script monitors the server’s status until it becomes healthy.
-
Once the
server health waitingservice returns 200, the startup page HTML redirects to the main Streamlit application.- The vector database is queried.
Step 1.2: Waking up the service
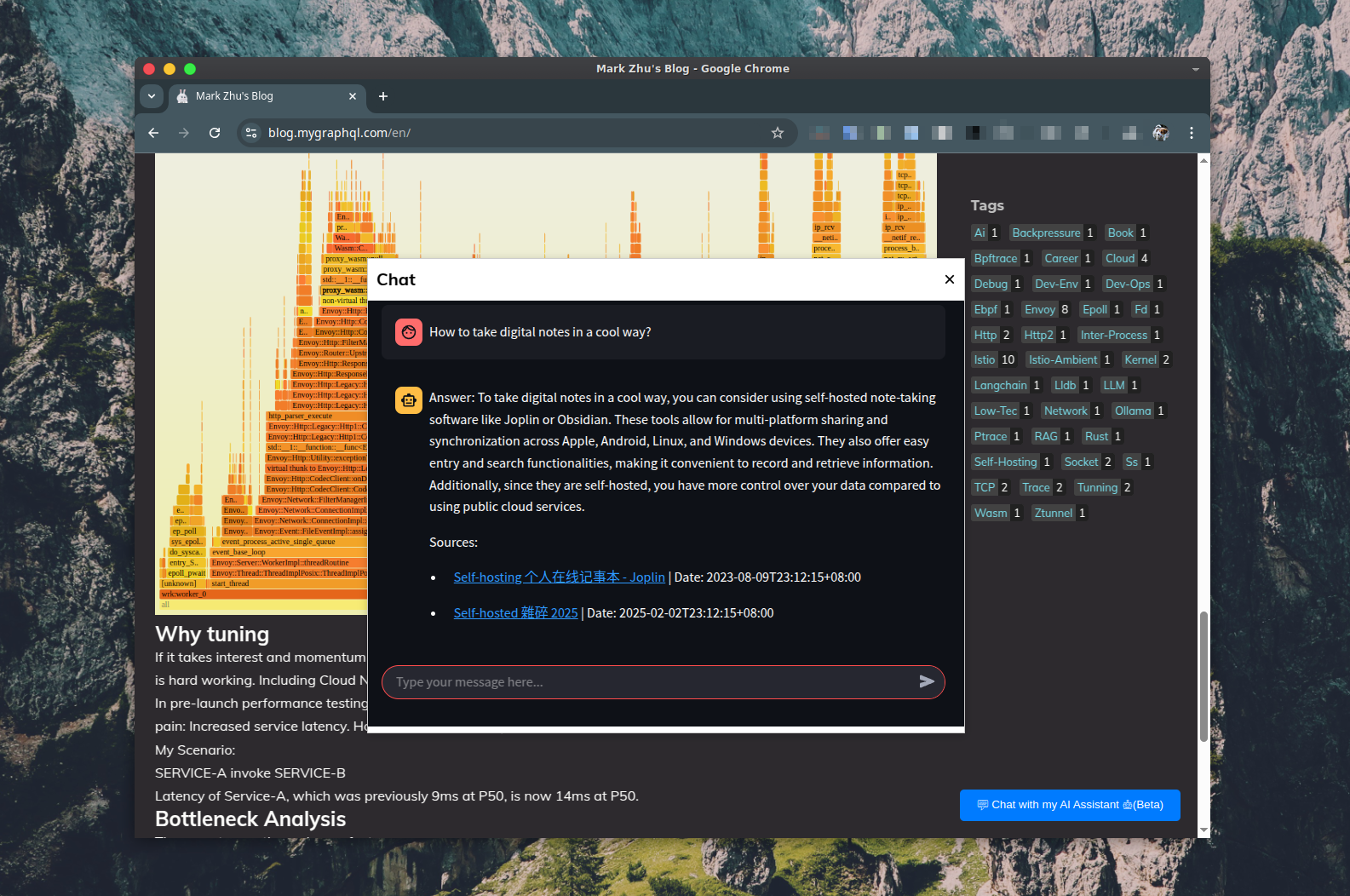
Some chat examples:
Data Sources
personal_resume.mdas part of the prompt.- Blog articles in Markdown format.

Workflow

Appendix: LangChain RAG Study Notes
LangChain’s documentation is notoriously bad, as acknowledged in Reddit’s LangChain groups. While learning LangChain, I found many examples lacked explanations of the implementation principles. So, I created diagrams to help myself understand and am sharing them here in case they help others.
My Notes on LangChain Docs: Build a Retrieval Augmented Generation (RAG) App - Part 2
A diagram illustrating LangChain’s RAG documentation: Build a Retrieval Augmented Generation (RAG) App: Part 2

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Conclusion
From an AI application perspective, this chatbot isn’t technically sophisticated. However, a few aspects made this project interesting:
-
Designing and implementing on-demand startup for the LLM (Ollama) server.
- Initially, I considered using
systemd-socket-proxydorenvoyto wake up the server upon access, but I found implementing it at the application (frontend) level was more user-friendly and simpler.
- Initially, I considered using
-
As my first LLM application attempt, it provided many learning experiences.
- Similar to my early Kubernetes learning journey, transitioning from confusion and frustration to debugging and troubleshooting was key to climbing the learning curve.
-
Heavy use of AI-assisted programming, particularly for Python and HTML/JavaScript, which I’m less familiar with.
Previously, I was skeptical about LLM-based application development. However, this experience reaffirmed the old saying: “Live and learn.” It’s better not to judge new technologies without hands-on experience. Much like how society once dismissed programming as impractical, I may have been viewing new technology with outdated perspectives. Perhaps recent years of tech bubbles have made me wary, or maybe aging has made my thoughts more rigid.