文章围绕“智能体开发生命周期(ADLC)”展开,系统拆解了企业如何将 AI Agent 从一次性 Demo 转化为可复制、高稳定的生产级系统。文章深入探讨了“构建、测试、部署、监控”四大核心阶段的工程实践与工具选择,并强调了成本控制、权限审计及资产复用等治理机制的重要性,为企业规模化落地 Agent 提供了清晰的工程化实战指南。
译者序: 本文翻译自: The Agent Development Lifecycle (ADLC) 。 作者 Harrison Chase,是 langchain 的联合创始人和 CEO 。 原文发表于 May 9, 2026 。 本文是我在数个面试时,被问及 AI Agent 开发相关问题时,感觉自己有一些欠缺,于是找到很多相关行业经验的人的文章,这是我觉得最有启发的文章之一。希望对你也有启发。 langchain 在 AI Agent 开发界的地位,就像 Spring 之于 Java 应用开发界的地位一样。本文使用了 LLM 作为翻译工具。
现在人人都在谈论 Agent(智能体)落地,大家都想赶紧把自己的 Agent 推向市场。
但真正厉害的团队,已经摸索出了一套能够批量、安全且系统化交付 Agent 的秘诀。他们信奉“天下武功唯快不破”,早早发布上线,从真实用户的反馈中学习,然后疯狂迭代。他们绝不把 Agent 当成一次性的 Demo(功能演示)或孤立的自嗨项目。
相反,他们构建了一套完善的智能体开发生命周期(Agent Development Lifecycle,简称 ADLC)。这套生命周期就像一个闭环的推进器,把零散的实验性尝试变成了一个可复制的系统,从而实现持续交付、持续学习并不断进化。
这个生命周期主要由四个部分组成:
构建 (Build) → 测试 (Test) → 部署 (Deploy) → 监控 (Monitor)
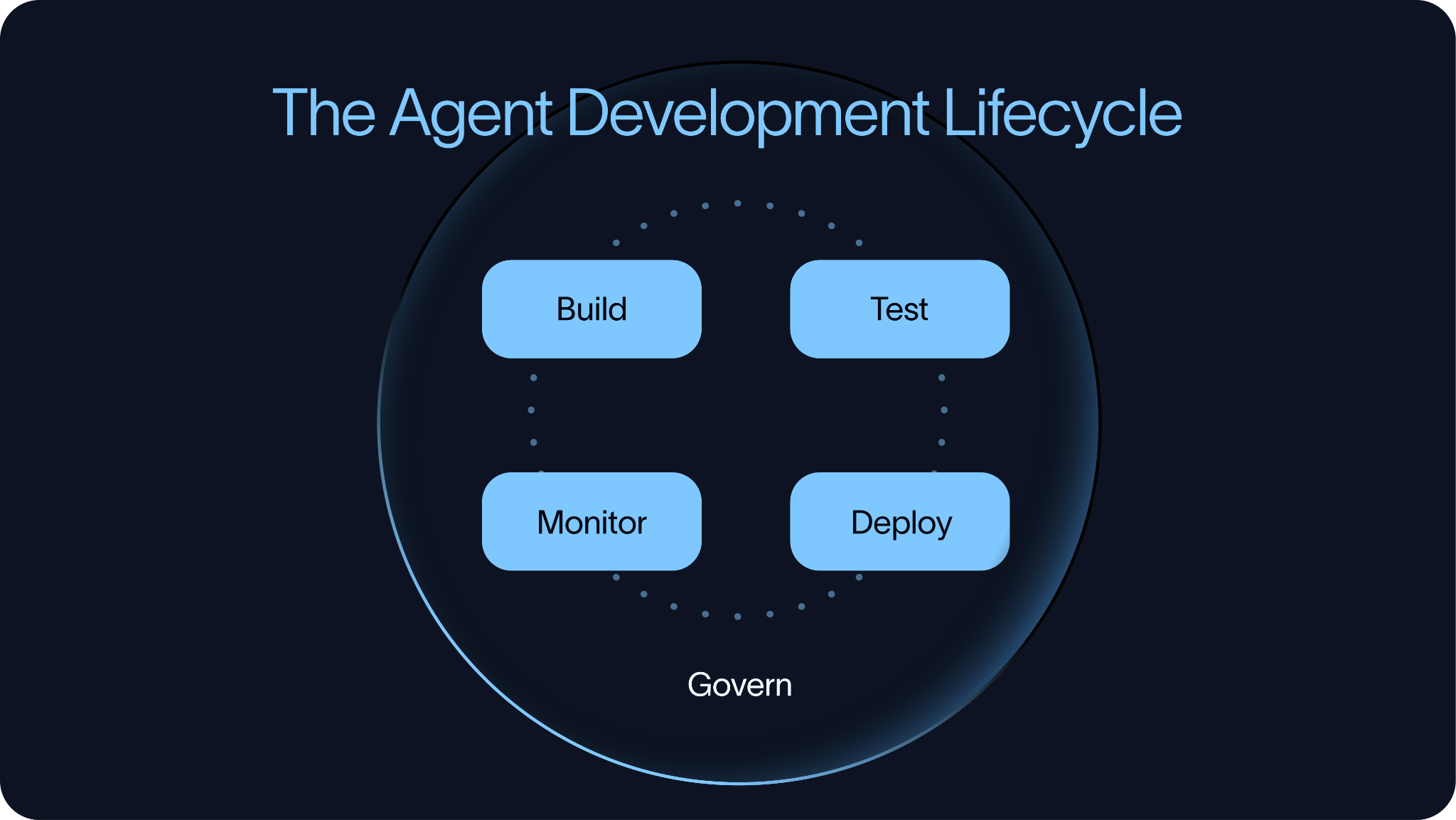
这个顺序可不是乱排的。测试应该在 Agent 真正进入生产环境之前就介入,而不是等上线了才去抓瞎。团队需要在部署前对 Agent 进行充分评估,以受控的方式进行发布,紧密监控其在生产环境中的实际表现,并将这些宝贵的实战经验反馈到下一轮的构建和评估循环中。
如果只是搞定一个单一的 Agent,这套流程可以玩得很轻量。但当你要管理成百上千个 Agent 时,它就会演变成一场基础设施和架构治理的硬仗。团队需要一套共享的方案来控制成本、管理工具(Tools)的访问权限、审计工具调用(Tool Calls)、复用上下文,并明确界定哪些环节必须引入人工介入(Human-in-the-loop)。
能不能把 Agent 从“碰巧成功一次的 Demo”变成“稳定输出的工程常态”,关键就在于你是否建立了对路的开发生命周期。
构建 (Build)
构建阶段是团队拍板决定要打造什么类型的 Agent 系统,以及选择哪种抽象层级(Level of Abstraction)的地方。
这个领域的工具链非常丰富。有些是“代码至上”(Code-first)的硬核路线,有些则是低代码或零代码(No-code / Low-code)的亲民路线。有些工具死磕抽象概念,而另一些则专注于为 Agent 提供现成的运行大礼包——包括 Prompt(提示词)、Tools(工具)、Skills(技能)和状态管理(State)。

在代码至上这一派,大家经常会用到开源框架和脚手架。比如 LangChain 生态里的 LangChain、LangGraph 和 Deep Agents。LangChain 之外,像 CrewAI 和 Claude Agents SDK 也是很热门的选择。
这些工具其实活跃在技术栈的不同层级:
- Agent 框架 (Agent Frameworks):主要盯着“抽象”下功夫。它们帮开发者把模型调用、工具、提示词、检索(Retrieval)、结构化输出(Structured Outputs)和 Agent 循环(Agent Loops)愉快地揉合在一起。LangChain 和 CrewAI 就是这类的典型代表。
- Agent 运行环境 (Agent Runtimes):核心在“执行”。它们是那些需要处理复杂状态、控制流、持久化(Durability)和人工干预的 Agent 的坚实后盾。LangGraph 是 LangChain 生态里最典型的例子,它能让你构建出可以分支、循环、暂停、恢复并随着时间持久化状态的智能体系统。
- Agent 脚手架 (Agent Harnesses):专注于“搞定事情”。它们为那些耗时较长的任务提供周边的支撑结构:比如 Prompt、Skills、MCP 服务器(Model Context Protocol)、Hooks(钩子)、中间件(Middleware),有时甚至还带一个文件系统。Deep Agents 和 Claude Agent SDK 走的就是这个路线。
分清这些概念至关重要,因为每个人嘴里说的“做个 Agent”,含义可能天差地别。
对于一个简单的应用,也许写个工具调用的死循环就完事了。但对于一个高阶 Agent,你可能得通宵达旦地写 Prompt、定义 Skills、接入 MCP 服务器、配置中间件,还要搭一个可以让 Agent 随着时间推移不断检索或更新的上下文口袋。
无代码构建
当然,构建阶段也少不了无代码和低代码的参与。像 LangSmith Fleet、Claude Cowork 和 n8n 这样的工具,让更多非技术人员也能撸起袖子参与到 Agent 的开发中来。这非常关键,因为往往最懂业务工作流的人,并不是敲代码的那批人。
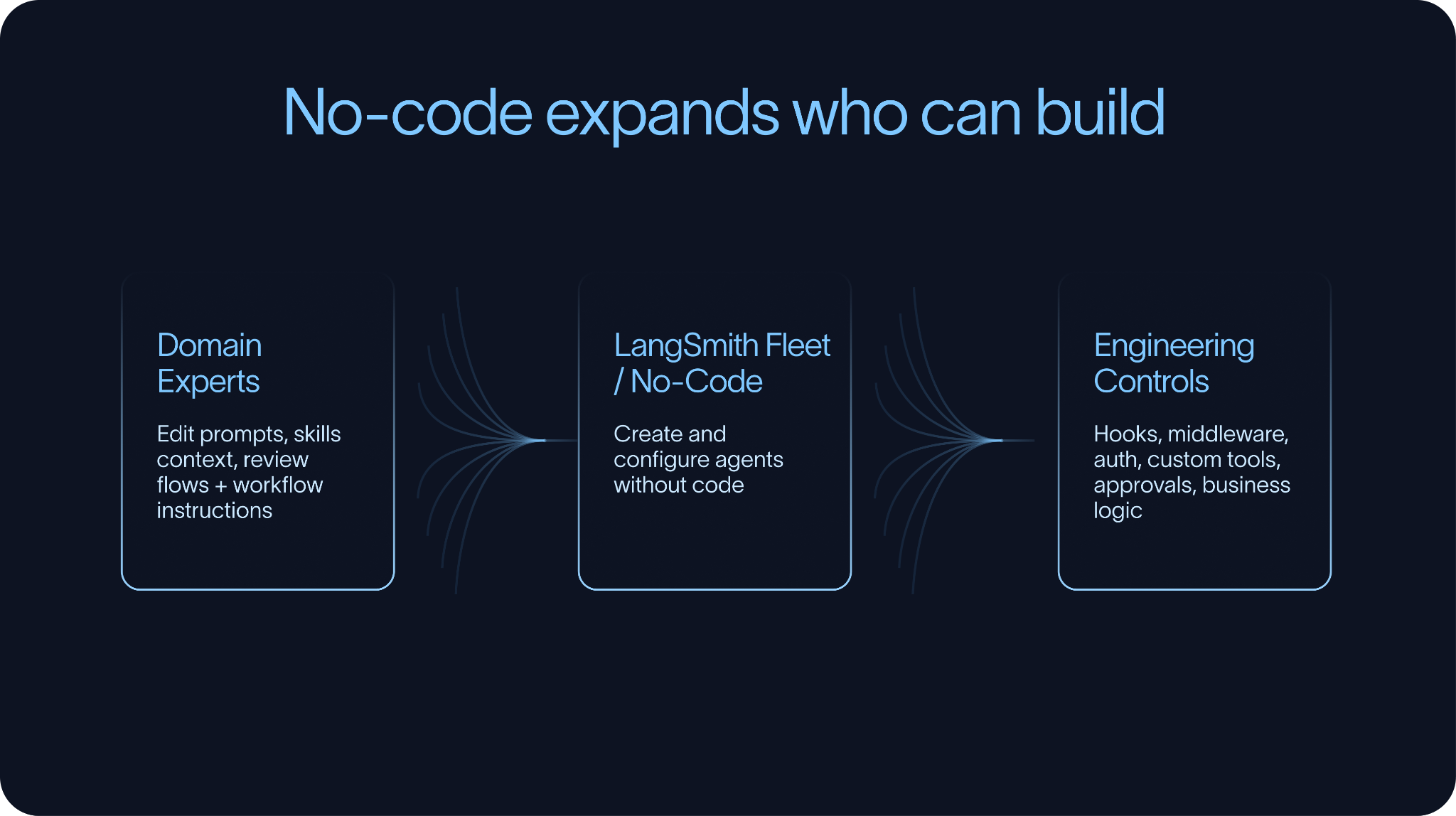
不过,无代码工具好用,并不代表能完全甩掉工程控制。随着系统越来越复杂,团队通常需要通过代码来扩展或覆盖某些行为。这时候 Hooks 和 中间件 就成了香饽饽,因为它们允许团队在工具调用、上下文处理、人工审批、鉴权或业务规则周围塞进自定义逻辑,而不需要每次都苦哈哈地从头重构 Agent。
最理想的构建环境应该满足:“让简单的事情保持简单,让复杂的事情变得可能”。它既能让行业专家轻松修改 Prompt、Skills 和上下文,又能把可靠性、可测试性和治理权限牢牢交到工程师手里。
测试 (Test)
在把 Agent 推上线之前,团队得有个靠谱的方法来回答一个灵魂拷问:这玩意儿真的准备好了吗?
这并不意味着你在所有人用上它之前,非得憋出一个完美的评估套件(Eval Suite)——这在实际开发中很不现实。它的真实含义是,你至少要部署足够的评估机制(Evals),用来抓出那些低级的翻车现场、做做版本对比,别闭着眼睛瞎上线。
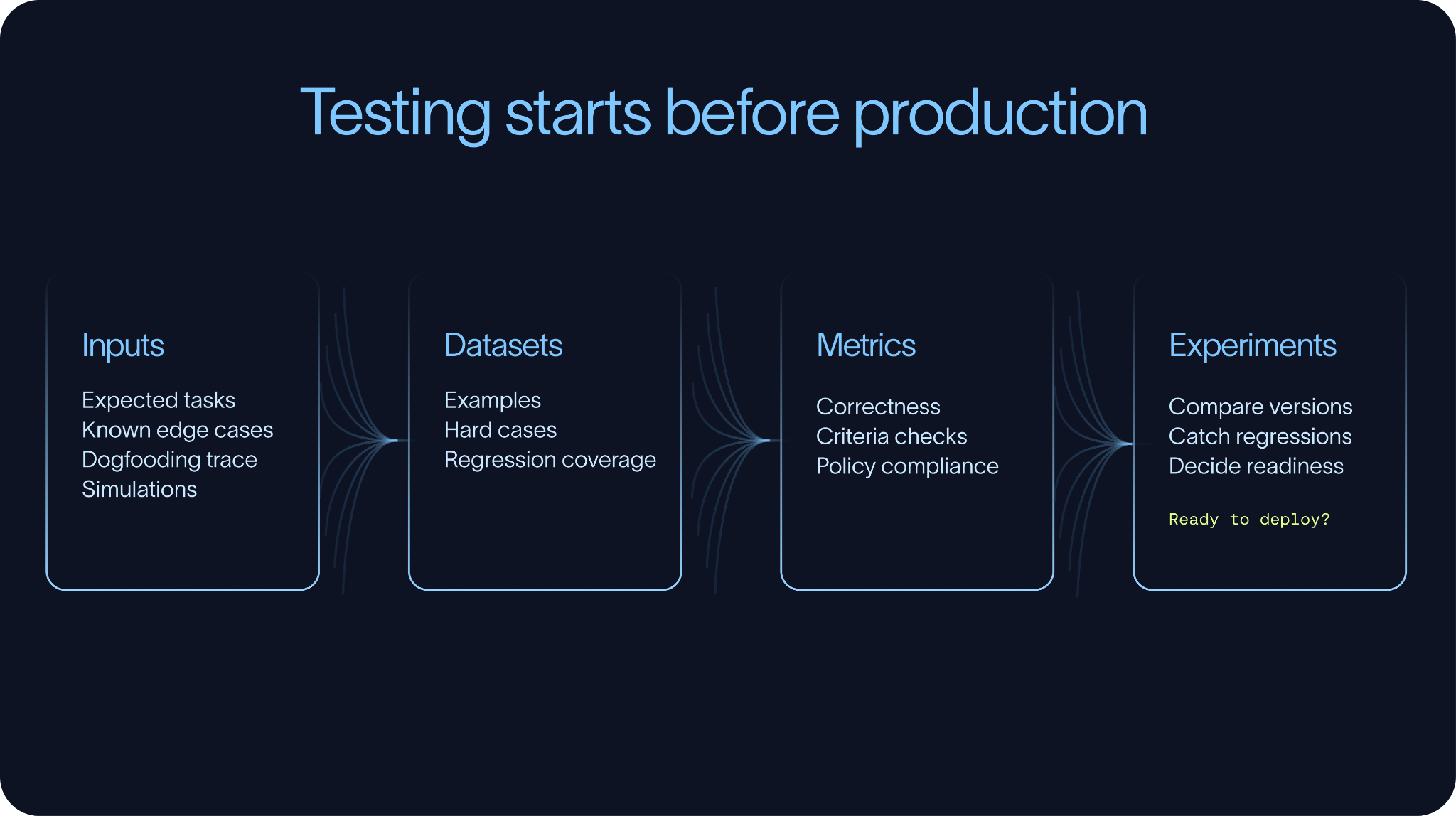
大多数评估工作流都是从一个小规模的代表性任务数据集(Dataset)开始的。这里面的测试用例,一部分来自拍脑袋预期的用户场景,另一部分则来自手动测试、团队内部试用(Dogfooding)、客服工单、历史 Trace 记录或者已知的极端边界情况(Edge Cases)。随着时间推移,生产环境沉淀下来的 Trace 会让这个数据集变得越来越强,但测试工作在上线前就得跑起来。
数据集与指标 (Metrics)
数据集是团队沉淀经验的“记事本”。没有它,只要你一改 Prompt、升级模型或者更新工具,以前踩过的坑保准100%重新踩一遍。
至于选什么度量指标,得看具体任务:
- 有标准答案的场景:比如 Agent 有没有提取出正确的值?有没有选对标签?有没有更新对字段?这类任务简单粗暴,直接量化正确率(Correctness)就行。
- 没有唯一标准答案的场景:比如让 Agent 写一封回信、总结一段对话、决定要不要升级到人工客服,或者完成一个有很多条路通往终点的任务。这时候,团队就得依赖基于标准的评估(Criteria-based Evaluation)。我们要考核的是:它的回答是不是基于事实的(Grounded)?有没有严格遵守公司政策?有没有在模糊时主动追问?或者有没有拖泥带水地调用了一堆没用的工具?
实验 (Experiments)
实验是连接数据集、指标与版本迭代的桥梁。通过跑实验,团队可以用同一个评估集,去横向评测不同的 Prompt、基座模型、检索策略、工具 Schema 以及编排模式。跑的目标多了,你一眼就能看出新版本到底是在原地飞升,还是在开倒车。
重申一下,我们的目标不是第一天就做出满意的完美 eval 组合,而是先搞一个及格线,然后小步快跑不断优化。最核心的评估数据集,往往都是被那些最刁钻的失败案例喂出来的——先是开发和内部试用阶段的毒打,接着是生产环境丢过来的真实暗器。
模拟 (Simulations)
模拟(Simulation)是测试环节的另一个重头戏。
许多 Agent 都是多轮交互系统(Multi-turn Systems)。它们不只是简单地一问一答,而是需要对话、搜集信息、调用工具、更新状态,还要从各种模棱两可的语境中自己缓过神来。对于这类 Agent,单轮评估(Single-turn Evals)连塞牙缝都不够,团队必须安排上多轮评估和端到端的模拟交互。
语音 Agent 是最典型的例子,但这种模式其实无处不在。任何需要拉锯几个回合的 Agent 都需要模拟测试。比如:一个客服 Agent 需要面对一个正在气头上的客户,它得懂追问、查订单状态,还得拿捏要不要一键呼叫主管;一个 Code Agent(编程智能体)得去翻代码库、改代码、跑测试,还要根据报错反馈继续改;一个内部审批 Agent 在采取行动前,也得先把缺失的信息补齐。
好的测试习惯能帮团队彻底告别“凭感觉(Vibes)优化”的玄学阶段。它把预期行为变成数据集,把数据集变成实验,再把实验变成更强的新版本。上线后,监控系统则会源源不断地输送真实世界的翻车案例,给测试集持续充能。
部署 (Deploy)
当一个 Agent 历经千锤百炼并通过评估后,它需要一个能让它稳稳运行的家。
对于一些逻辑简单的 Agent,部署起来跟传统应用没啥两样。但很多高级 Agent 要干的活可复杂得多:它们可能需要长时间在线(Long-running),一会调用工具,一会停下来等人类审批,一会写写文件,还得在系统崩溃后能自己爬起来继续干,并且在几天的跨度里死死记住上下文。
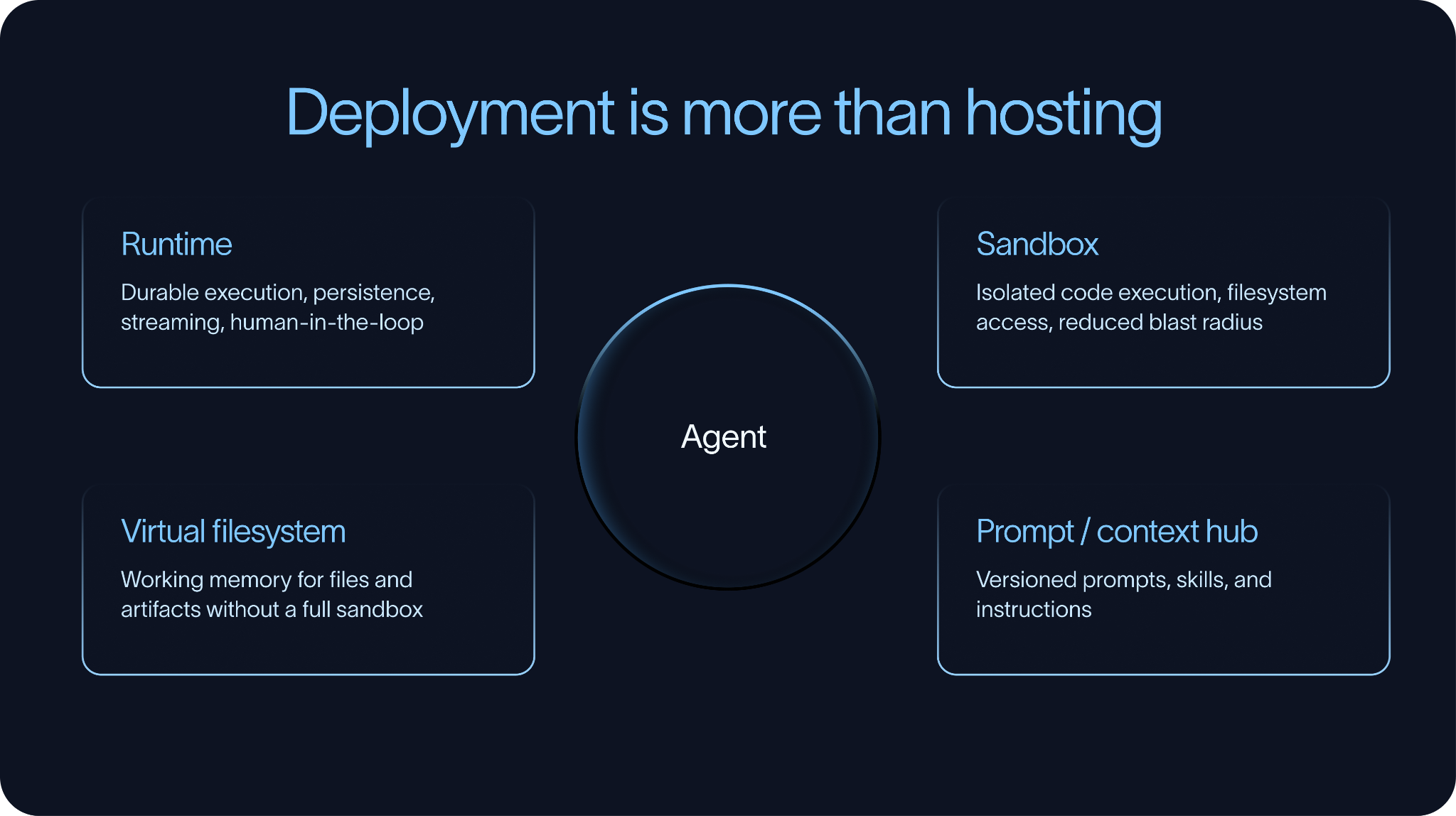
正因如此,运行环境(Runtime)才显得格外重要。
一个生产级别的 Agent Runtime,通常必须支持持久化执行(Durable Execution)和人工干预(Human-in-the-loop)模式。持久化执行意味着 Agent 可以随时“存档”进度,哪怕中间断电宕机了,连上网还能继续接着干,不至于让前面的心血白费。人工干预则是指 Agent 在遇到要紧事、需要审批或需要澄清时,能够随时按下“暂停键”,等人类介入。
市面上已经有一些现成的商业或开源方案了。LangSmith Deployment 提供了专门部署和管理 Deep Agents 及 LangGraph 的底层基础设施;AWS AgentCore 也是一个不错的托管型 Agent Runtime。另外,很多团队也会基于 Temporal 这类工作流引擎自己手搓 Runtime,特别是如果他们的技术栈里本来就用 Temporal 来跑其他长耗时业务的话。
沙箱 (Sandboxes)
很多 Agent 还需要一个专属的“行刑场”——执行沙箱。
现在的 Agent 权力越来越大,动不动就要自己写代码、跑脚本、翻看文件、转个 PDF 或者在文件系统里横着走。这种情况下,团队必须严防死守,把它们框在一个安全的地方。沙箱就是标配。它提供了一个带文件系统访问权限的隔离执行环境,哪怕 Agent 哪天“发疯”删库跑路,也能把爆炸半径(Blast Radius)锁在沙箱内部。
这方面的代表工具有 LangSmith Sandboxes、Daytona 和 E2B。
当然,不是每个 Agent 都需要顶配沙箱。有时候它只是需要一个存取文件的地方,那一个虚拟文件系统(Virtual Filesystem)就够了。Deep Agents 就支持这种玩法,允许 Agent 把文件当成动态运行内存来用,而不必在沙箱里执行任何未知的危险代码。它的底层可以简单地挂载在 Postgres 或 S3 上。
上下文中心 (Context Hub)
在部署阶段,还有一个经常被大家遗忘的角落:如何管理 Prompt 和上下文。
我们要明白,Agent 最核心的灵魂往往不是那些写死的应用代码,而是 Prompt、检索上下文、Skills 和任务指令。这些东西的变动频率可比业务代码高多了,而且通常需要非程序员(比如产品或运营)去直接调整。
这就催生了对 Prompt/Context Hub(提示词/上下文中心) 的刚需。这是一个能对非代码资产进行存储、版本控制、Code Review 和一键更新的中央仓库。有了它,团队不需要重新走一遍漫长的 CI/CD 部署流程就能秒级调整 Agent 的行为,也能让业务专家牢牢掌控他们最熟悉的业务上下文。
在实际工程中,部署绝对不仅仅是把一段代码扔到服务器上。它的本质是为 Agent 提供一套集成了 Runtime、安全执行环境以及上下文管理系统的全套“生存空间”。
监控 (Monitor)
一旦 Agent 昂首挺胸奔向了生产环境,团队就必须睁大眼睛,看清楚它们在真实世界里到底在干嘛。
这也是监控 Agent 让人头秃的地方——它跟传统软件监控完全不是一个频道。QPS、延迟(Latency)、算力成本、报错率和可用性(Uptime)这些传统指标固然重要,但它们只能看个皮毛。一个 Agent 完全可以返回一个 HTTP 200 OK,但在业务层面上把事情办得一塌糊涂:它可能调用了错误的工具、看偏了上下文、绕过了必须的人工审批,或者一本正经地胡说八道(幻觉)。
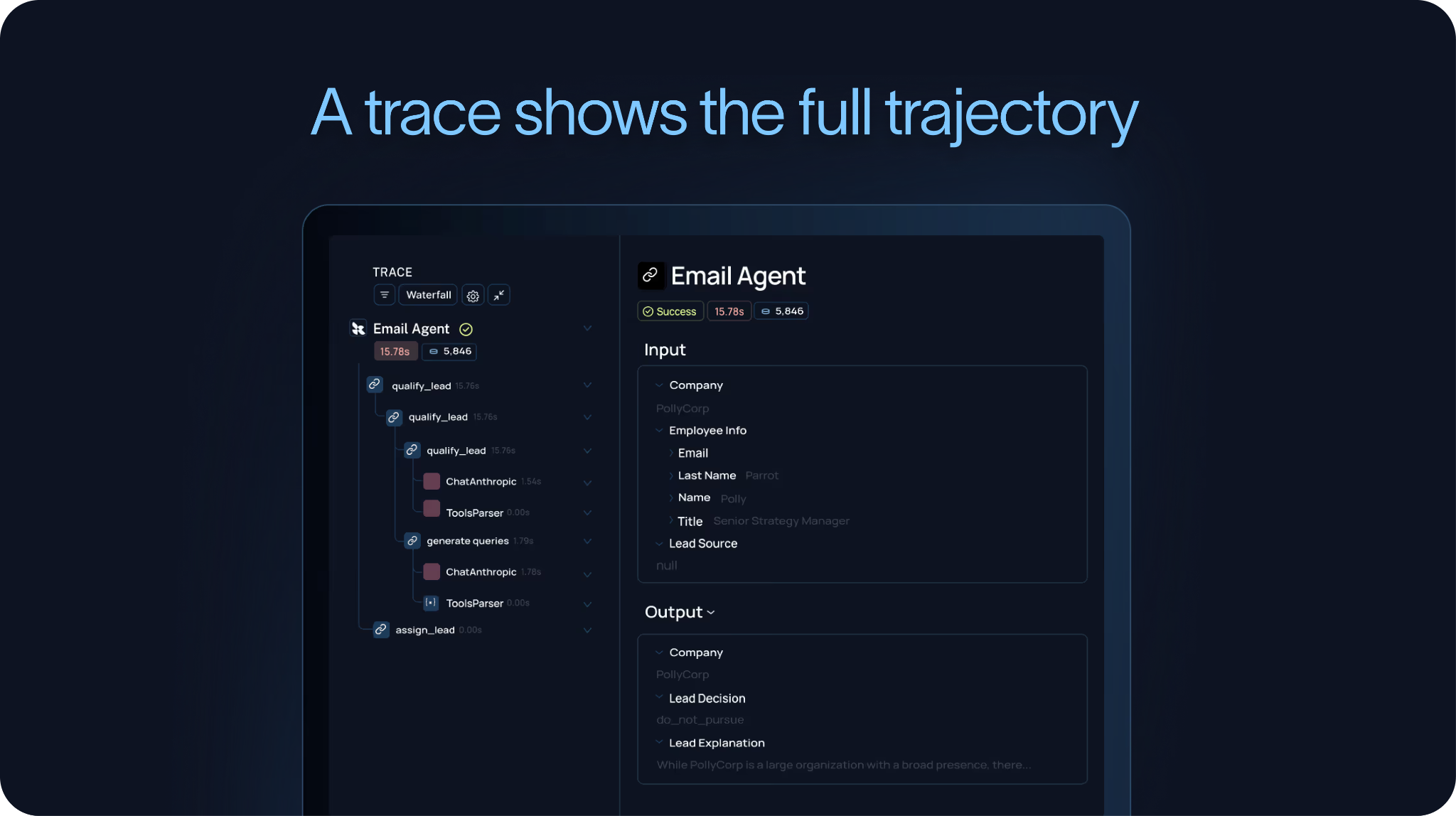
想要看穿这些隐蔽的失败,团队唯一的指望就是 Traces(调用链路追踪)。
一条 Trace 记录了 Agent 的全量心路历程:它收到了什么输入、悄悄调了哪几次大模型、触发了什么工具、工具返回了啥,以及最终是怎么憋出答案或采取行动的。只有细到这个颗粒度,你才能破案,看清 Agent 到底在哪里走调了。
这也是为什么业内一直坚信 Agent 可观测性是评估的燃料,并且 Agent 的优化闭环始于 Trace。如果你连它的行为轨迹都看不见,就别谈什么调试 Bug,更别想把这些失败案例转化成未来的测试用例了。
信号收获 (Signals)
光有 Trace 还不够,监控系统还得学会从中自动“捞信号”。
有些信号可以通过 LLM-as-a-judge(大模型充当裁判) 的自动化评估来获取。比如,让一个特定的大模型去给生产 Trace 打分:Agent 有没有正面回答问题?有没有违反合规?语气够不够客气?任务完成得香不香?还有些信号可以玩得很简单——直接上正则表达式(Regex),去抓有没有出现敏感词、有没有误调用禁用工具,或者有没有触发已知的报错高危区。
这些信号不仅能用来做质量卡点,还能顺便当成产品数据分析(Product Analytics)。它们能清晰地告诉你:用户最喜欢派 Agent 去干什么活?Agent 最容易卡在哪个泥潭里?用户对它们进行纠偏的频率有多高?用户在哪个环节吐槽最多?
反馈机制 (Feedback)
反馈是监控的另一块核心拼图。
孤零零地存 Trace 没多大用,团队得把反馈数据和 Trace 死死绑定在一起。这些反馈可以来自前面提到的 LLM 裁判、正则信号,也可以来自人工审计员或者用户在前端界面上点的赞和踩(Thumps up/down)。在 LangSmith 里面,团队可以直接把用户反馈挂载在底层的具体 Run(运行实例)上。这样一来,当你看到“用户气炸了”的反馈时,就能顺藤摸瓜秒定位到“哦,原来是三步之前 Agent 选错了工具”。
仪表盘 (Dashboards)
最后,团队需要直观的仪表盘和告警系统来监控大盘趋势。
一个合格的 Agent 仪表盘应该把用户量、反馈趋势、平均延迟、Token 成本、工具调用频次、裁判打分以及高频报错模式一网打尽。告警阈值也得安排上:一旦发现延迟飙升、钱包大出血、工具频繁报错、用户好评率暴跌或者合规踩雷,必须立马大喇叭报警。
说到底,好的监控不是看你的服务器有没有宕机,而是看你的 Agent 有没有在做正确的事,并且是不是越做越聪明。
最牛的监控系统,最后都会把力量反哺给测试阶段。那些在线上让人拍案惊奇的 Trace 会变成数据集里的新用例,那些翻车频率极高的雷点会变成新的测试指标,生产环境的真实表现,才是下一轮迭代最坚实的基石。
持续迭代 (Iterate)
走得最远的企业,在智能体开发生命周期里往往跑得又快又稳。
他们从不追求憋大招、指望一上线就完美无瑕。相反,他们的战术是:先做一个能解决具体问题的小工具,测到心里有底就赶紧上线,在受控的生产环境里观察真实表现,然后把线上学到的经验源源不断地输送给下一个新版本。
这绝不等于盲目乱切版本。敢这么玩的底气,来自于强大的可观测性。
手里握着数据集、实验看板、Tracing 链路、反馈管道和可视化仪表盘的团队,就像开了全图挂。他们可以在大面积推广前做 A/B 测试,能一秒定位线上哪里翻了车,能把线上失败当成养分喂给测试集,从而彻底告别“看天吃饭、凭感觉调优”的盲盒时代。
这就是工业界常说的“爬山算法”(Hill-climbing),也是 Agent 系统持续变强的唯一正道。
最有效率的团队永远在死磕那些难啃的 Bad Cases。看透了 Agent 为什么掉链子之后,转手去调整 Prompt、工具配置、检索策略、微调模型、中间件或整体工作流。接着重新跑一遍 Eval 评估,部署新版本,然后静静等待监控系统带回下一批更有挑战性的极端用例。
但在大企业内部,真正的难点在于:如何让这个闭环在各个团队之间大范围复制?
如果每个业务团队都要从零开始去手搓自己的评估框架、部署底座、Tracing 系统、反馈管线和监控大屏,那这家公司的 Agent 业务基本上就告别“兵贵神速”了。真正聪明的组织会重金砸在共享基础设施上,让一线的兄弟们能轻装上阵,专注于业务本身,而不需要一遍遍重复造轮子。
这就是为什么说,智能体开发生命周期最终会变成一项组织工程和运营规范。
治理与合规 (Govern)
治理(Governance)像一个保护罩,罩住了整个智能体开发生命周期。
如果公司里只有一两个 Agent,靠几个人口头对齐、轻量控一下完全没问题。但当各业务线开始搞 Agent 军备竞赛时,如果没有治理,公司很快就会陷入泥潭:没人知道到底有多少个 Agent、没人盯着它们的行为、账单贵得要死,而且谁也说不清这些 Agent 到底有多大权限。
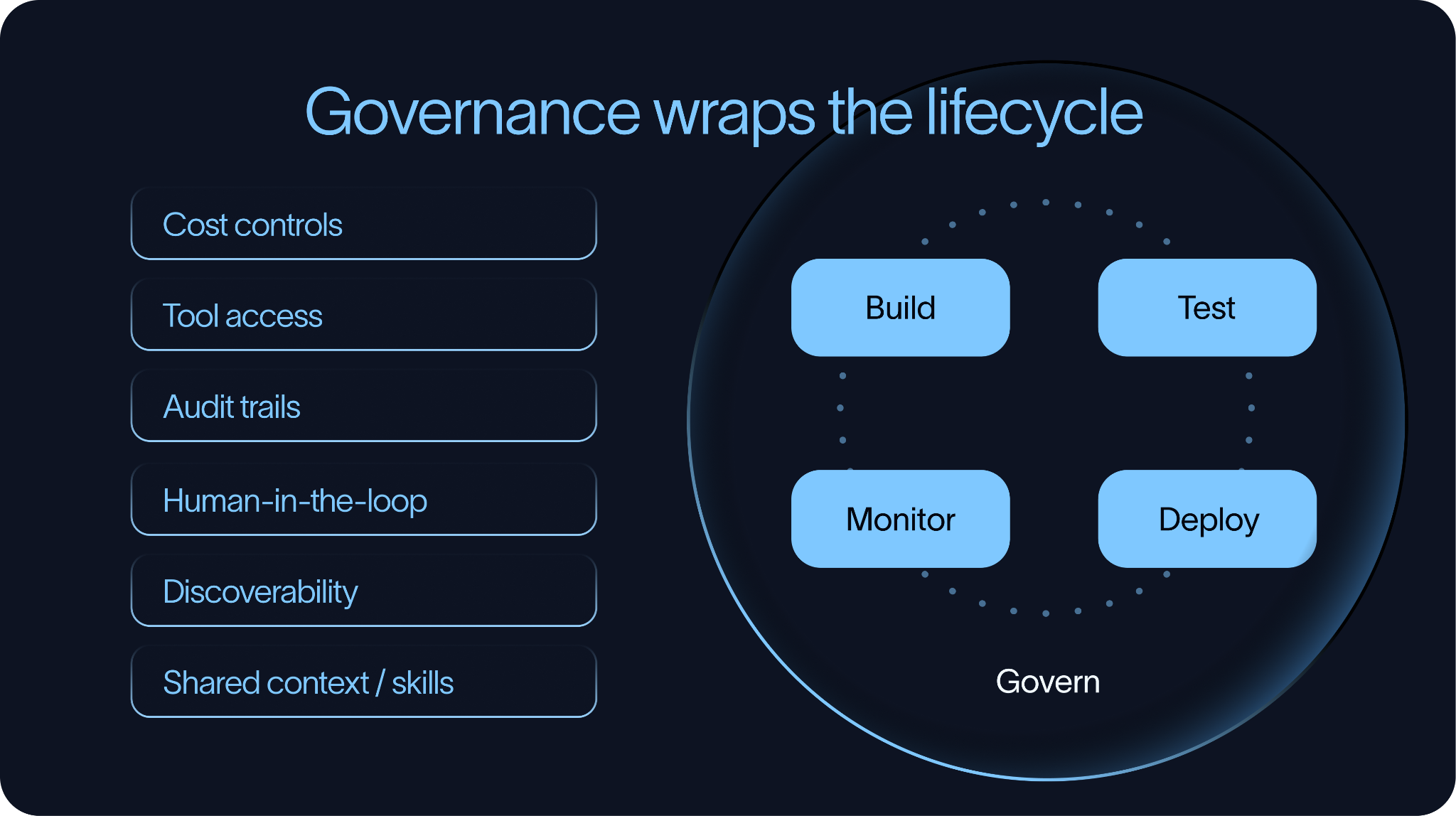
成本治理
第一个要直面的大怪兽就是成本。
Agent 的开销极其容易失控。因为它们一运转起来,往往伴随着套娃式的模型调用、动辄几万 Token 的长上下文窗口、没完没了的工具重试,甚至一跑就是几个小时。组织必须通过预算卡点、用量监控、超额告警,以及清晰的看板(看清到底是哪个 Agent、哪个团队、哪个模型或工具在疯狂烧钱)来把成本关进制度的笼子里。
工具权限控制
第二个烫手山芋是工具访问权限。
Agent之所以能干活,是因为我们给了它调用工具的“手和脚”,但这同样带来了巨大的安全隐患。团队必须制定清晰的黑白名单:哪个 Agent、在什么条件下、代表哪个具体用户,才能调用哪个特定的外部工具?
这时候**审计日志(Audit Trails)**就成了救命稻草。一旦某个 Agent 线上调用了某个工具,组织必须能一键追溯:是哪个 Agent 调的?传了什么参数?返回了什么结果?到底是谁或者哪条安全策略授权它这么干的?工具调用往往直接产生业务后果(比如扣款、发货、删数据),所以必须做到100%可监控、可审计。
**人工干预(Human-in-the-loop)**同样是治理中不可或缺的安全阀。
绝对不能把所有工具调用都交给全自动驾驶。一些高危操作(比如涉及真实客户、财务划款、敏感数据修改或生产环境配置变动)必须死死卡住,等待人类点下确认键。这种人工干预的工作流,最好在 Agent 架构设计的第一天就埋进基因里。
资产的可发现性与复用
第三个治理挑战是资产的沉淀、发现与复用。
随着各团队开足马力,公司里会快速堆积出海量的优质资产:优秀的 Prompt 模板、封装好的 Skills、工具、高质量检索源、合规 Policy,甚至一些可以直接嵌套的子 Agent。如果缺乏良好的发现和治理机制,大家很快就会陷入信息孤岛,无数人在不同的角落重复发明一模一样的轮子,不仅浪费算力,还会导致输出风格和合规标准的精神分裂。
共享的上下文和资产必须做到“可见、可查、可复用、可管”。
这一点在 Skills(技能) 的复用上体现得淋漓尽致。一个封装好的 Skill 可能凝聚了某个团队好几个礼拜的心血——它包含了特定业务的工作流、特定的文案风格、垂直领域的专业 SOP 或者是用某个破工具的独门秘籍。如果 A 团队已经把这个 Skill 调教得很完美了,B 团队应该能一键搜索并直接拿来调用,而不是自己再去踩一遍坑。
做治理的目的从来不是为了给业务团队“裹脚”或拖慢速度,而是为了帮大家装上安全气囊,让大家在规模化飙车的时候不至于翻车,在方向盘不失控的前提下把油门踩到底。
总结
走在时代前沿的团队,早就已经切换到了这套全新的游戏规则中。他们坚信“小步快跑,尽早上线”,但绝不盲动。他们在部署前死磕评估,在上线后死盯着行为 Trace,并把从真实世界里买来的教训,原封不动地变成下一代产品的升级燃料。
这就是让 Agent 开发从“玄学 demo”走向“严谨工程”的必由之路。也是决定你的 Agent 到底是一个只能在发布会上亮个相的玩具,还是一个能真正替公司下地干活的生产力工具的分水岭。