
引
性能测试、压力测试、业务系统性能容量评估。这 3 件事,可以认为是大部分程序员/软件开发从业者都需要面对的事。但,奇怪的是,很多人花了很多时间去做完成这些工作任务,却很少有人有计划地、系统地花时间去学习和研究相关的知识。
想一想,我们花了很多时间在学习各种光环中的 “新技术”: Cloud Native / Service Mesh / ML / Go / Rust ….。看公众号、买书、加入相关社区。最后成功成为一个技术表演者。
但对于我们必然要面对的问题:系统性能,跟其中 20 年以上的老技术知识,却只想在遇到问题时才搜索一下或 stackoverflow 一下。其原因大概为:
- 投入产出比低,能应付就好
- 出性能问题前,这东西不影响 KPI,做好了没人知道
- 出事了救火也很难成功,想当 Hero,最后多成炮灰
- 一不小心找出问题和优化方法,还因指出了原来的问题而和相关的人 “结下梁子”
- 现代软件开发团队清晰的人员职责划分一定程度上引起系统性能问题
其中可能最有争议和最需要解释的是第 5 点:
- 架构设计期:架构师,花在性能上的考量相当有限的。
- 开发期:程序员,功能的正确性认为是开发的主要职责,花在性能上的考量相当有限的。
- 性能测试期:性能QA,这是最后的保底一环了。发现问题后,回到
1.架构设计或2.开发期上解决。- 上线后观察期:运维监控,这是运用
可观察性做到快速定位
可见,性能问题大都在 3、4 考虑。 1、2 考虑时,很容易被说成 过早优化 。而 1、2 其实是最考验架构师和程序员在性能上的功力、敏感度、职业素养、平衡(trade off)各方因素的时候;其中最关键的,应该是定位哪儿是系统的性能压力关键路径,并将主要和有限的精力集中解决。
抽象思维
上面的问题,如果进一步提炼,可以认为,均出自我们习以为常,一直行之有效的思维方法:
抽象与自顶向下(Top-down)。这个思维模式一直非常成功:
- 组织公司、组织分工时,我们有自顶向下的架构
- 系统开发时,有
概要设计、详细设计 - 学习知识时,有 Mind Map(脑图)
那么这个曾行之有效的思维模式和工作方法,也应该可以用于系统性能这事上。
而事实上,不完全正确,有时甚至恰恰相反。
我经历的多数性能问题,多是在系统运行时,观察到应用层问题。然后调查后发现直接原因是系统底层软硬件资源的使用饱和,然后倒推回架构流程上的资源使用问题。
自顶向下(Top-down)的工作流程、设计方法、问题解决方法,均水土不服。而自底向上(Bottom-up) 的方法,更好地解决了问题。
现代思维喜欢抽象模式,但性能优化有时相反,越具体现实,优化的空间越大,当然优化方法也对条件和环境要求越严格。
不好意思,这个开场白太长了。不要睡着了。
现代 CPU 特性

上面说的全是概念,这里开始,来接地气。我环境中的 CPU是: Intel® Xeon® Gold 6230N,它有一堆特性,其中我关心的是:
| 特性 | 值 |
|---|---|
| Total Cores | 20 |
| 超线程:Total Threads | 40 |
| 基础频率:Processor Base Frequency | 2.30 GHz |
| 最大超频频率:Max Turbo Frequency | 3.50 GHz |
| 动态调频:Enhanced Intel SpeedStep® Technology | ✔️ |
| 动态调频:Intel® Speed Shift Technology/Hardware p-state(HWP) | ✔️ |
| 动态睿(超)频:Intel® Turbo Boost Technology | ✔️ |
| 动态睿(超)频:Intel® Turbo Boost Max Technology 3.0 | ✔️ |
| 超线程:Intel® Hyper-Threading Technology | ✔️ |
| Cache | 27.5 MB |
下面先大概介绍一下:
动态调频
首先,什么是 CPU 运行频率,可以看的Intel 的官方回答:What Is Clock Speed?。
Intel 有好几个技术会自动动态调整 CPU 运行频率:
- Enhanced Intel SpeedStep Technology (EIST) - Introduced with Pentium M, 2005
- Turbo Boost Technology(TBT) - Introduced with Nehalem in 2008
- Turbo Boost Technology 2.0 (TBT 2.0) - Introduced with Sandy Bridge in 2010
- Speed Shift Technology (SST) - Introduced with Skylake in 2015
- Turbo Boost Max Technology 3.0 (TBMT) - Introduced with Broadwell E in 2016
- Thermal Velocity Boost (TVB) - Introduced with Coffee Lake H in 2018
- Speed Select Technology (SST) - Introduced with Cascade Lake in 2019
P-State 阶梯频率
动态调频并不是 CVT 无级变速箱 🚗,是有级的 AT 变速箱 😏。Intel 给这些级别定义了一个术语:P-State。
CPU P-states represent voltage-frequency control states defined as performance states in the industry standard Advanced Configuration and Power Interface (ACPI) specification.
In voltage-frequency control, the voltage and clocks that drive circuits are increased or decreased in response to a workload. The operating system requests specific P-states based on the current workload. The processor may accept or reject the request and set the P-state based on its own state.
CPU P-states 表示在电源接口 (ACPI) 规范中定义为性能状态的电压频率控制状态。
在电压频率控制中,电路的电压和时钟响会因应工作负载而增加或减少。 操作系统根据当前工作负载向 CPU 申请特定的 P-state。 CPU 可以接受或拒绝请求,并根据自己的状态设置 P-state。
The majority of modern processors are capable of operating in a number of different clock frequency and voltage configurations, often referred to as
Operating Performance PointsorP-states(in ACPI terminology). As a rule, the higher the clock frequency and the higher the voltage, the more instructions can be retired by the CPU over a unit of time, but also the higher the clock frequency and the higher the voltage, the more energy is consumed over a unit of time (or the more power is drawn) by the CPU in the given P-state. Therefore there is a natural tradeoff between the CPU capacity (the number of instructions that can be executed over a unit of time) and the power drawn by the CPU.可见 Linux 中
p-state有一个别名:Operating Performance Points。原因很简单,p-state是 Intel 的命名,Linux 需要支持众多厂商,需要一个抽象定义。
以下是一个P-State 级别例子:
| State * | CPU clock (MHz) | CPU clock (percentage) |
|---|---|---|
| P0 (High Frequency mode (HFM) )/Base Frequency | 2801 | 100% |
| P1 | 2800 | 99% |
| p2 | 2700 | 96% |
| … | … | … |
| P13 | 1400 | 49% |
| P14 | 1300 | 46% |
| P15 (Low Frequency Mode (LFM)) | 1200 | 42% |
上面得知 CPU 频率有好几个P-State档位,那么谁去换档?Intel 有两个可选:
- 软件操作系统
- Enhanced Intel SpeedStep Technology
- CPU 硬件
- Speed Shift Technology
Enhanced Intel SpeedStep - 操作系统控制 CPU 频率
Enhanced Intel SpeedStep® Technology
Enhanced Intel SpeedStep® Technology enables OS to control and select P-state. The following are the key features of Enhanced Intel SpeedStep® Technology:
- Multiple frequencies and voltage points for optimal performance and power efficiency. These operating points are known as P-states.
- Frequency selection is software controlled by writing to processor MSRs. The voltage is optimized based on the selected frequency and the number of active processors IA cores.
Speed Shift - CPU 自动控制频率
Speed Shift 又叫 Hardware p-state(HWP)。在 Intel Skylake 和其后的 CPU 架构中,操作系统可以将 P-states 的控制权交回 CPU(Speed Shift Technology,Hardware P-states)
Intel® Speed Shift Technology is an energy efficient method of frequency control by the hardware rather than relying on OS control. OS is aware of available hardware P-states and requests the desired P-state or it can let the hardware determine the P-state. The OS request is based on its workload requirements and awareness of processor capabilities. Processor decision is based on the different system constraints for example Workload demand, thermal limits while taking into consideration the minimum and maximum levels and activity window of performance requested by the Operating System.
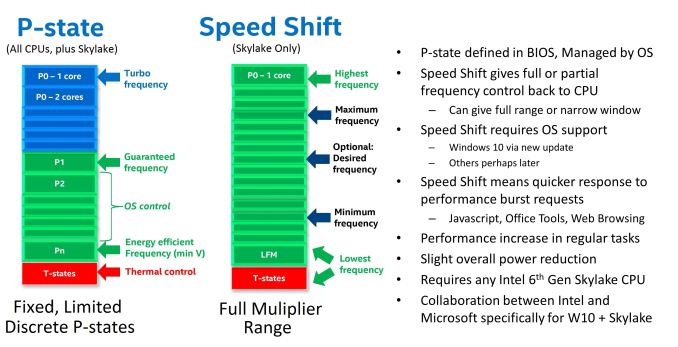
from [https://www.thomas-krenn.com/en/wiki/Processor_P-states_and_C-states]
动态短时 Turbo Boost(Intel 睿频)
Turbo Boost(Intel 睿频)
Intel 的官方回答:什么是英特尔 睿频加速技术?
Turbo Boost(睿频) 工作原理
CPU 并不总是需要以最大频率运行。有些程序更依赖内存来平稳运行,而另一些则属于 CPU 密集型。睿频加速技术就是用来解决这种不平衡问题的节能方案:它允许 CPU 在处理轻负载时以基本时钟速度运行,而在处理高负载时提升至更高的时钟速度。
以低时钟速率(处理器每秒执行的周期数)运行可以让处理器的功耗更低,从而减少热量。但是当需要更高的速度时,睿频加速技术会动态地提高时钟速率来进行补偿。这有时称为“算法超频”。
睿频加速技术可以在安全温度和功率限制内,将 CPU 速度提升到最高睿频。这样就可以提升单线程和多线程应用程序(利用多个处理器内核的程序)的性能。
什么是 Max Turbo Frequency (最大睿频)
处理轻负荷时,CPU 以其规格中列出的基本频率运行。(在使用节能英特尔SpeedStep® 技术调节 CPU 速度时,频率会更低。) 在处理标记为高性能的硬件线程时,英特尔® 睿频加速技术可将时钟速度提高到最大睿频。
例如,英特尔® 酷睿™ i9-9900K 处理器的基本频率为 3.60 GHz,最大睿频为 5.00 GHz。需要注意的是,根据所处情况,特定的CPU可能不会总是达到其最大睿频。速度的动态提升会根据工作负载和可用的热余量而变化。
在比较 CPU 时钟速度时,最大睿频是通常要记住的关键数字。它反映了处理器在超频前的峰值性能。除了内核数和高级功能外,这也是选购 CPU 时要考虑的重点因素之一。
Turbo Boost Max 技术 3.0 是什么
Intel 的官方回答:Get to Know Intel® Turbo Boost Max Technology 3.0
睿频加速 Max 技术 3.0 将软件与硬件巧妙结合。通过识别处理器的最快内核并让其处理最关键的工作负载,使轻量级线程性能得到优化。
睿频加速 Max 技术 3.0 的可用性和频率提升取决于多种因素,包括但不限于以下因素:
- 工作负载类型
- 活跃内核的数量
- 预估的电流消耗
- 预估的功耗
- 处理器温度
Turbo Boost Max 技术 2.0 与 3.0 的区别是什么?
Turbo Boost Max 技术 3.0 是 2.0 的增强版,可单独提升 CPU 最快内核的速度,同时将关键工作负载引导至这些已加速的内核。它可以将单线程性能提升高达 15%。英特尔® 睿频加速 Max 技术 3.0 不会取代英特尔® 睿频加速技术 2.0。前者对后者进行了增强,可大幅提高最快内核的频率,从而让用户能够更加灵活地获得卓越的处理器性能。
上面的引文,我划了一些重点。一切听起来很深奥且完美,但有些东西,是细思极恐的:
- CPU 频率和程序的实际CPU指令相关,有不可以控制的因素
- CPU 频率和处理器温度有关。想想机房空调的情况会影响你的程序性能,是不是好好玩?
Turbo Boost 技术的机制
下面是一个活跃 core 数和可以达到的最大 Turbo Boost 频率的关系例子:
| Mode(程序模式) | 基础频率 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Normal | 2,300MHz | 3,500MHz | 3,500MHz | 3,300MHz | 3,300MHz | 3,200MHz | 3,200MHz | 3,200MHz | 3,200MHz | 3,200MHz | 3,200MHz | 3,200MHz | 3,200MHz | 3,100MHz | 3,100MHz | 3,100MHz | 3,100MHz | 2,900MHz | 2,900MHz | 2,900MHz | 2,900MHz |
| AVX2 | 1,600MHz | 3,400MHz | 3,400MHz | 3,200MHz | 3,200MHz | 3,100MHz | 3,100MHz | 3,100MHz | 3,100MHz | 3,100MHz | 3,100MHz | 3,100MHz | 3,100MHz | 2,800MHz | 2,800MHz | 2,800MHz | 2,800MHz | 2,600MHz | 2,600MHz | 2,600MHz | 2,600MHz |
| AVX512 | 1,200MHz | 3,400MHz | 3,400MHz | 3,200MHz | 3,200MHz | 3,100MHz | 3,100MHz | 3,100MHz | 3,100MHz | 2,600MHz | 2,600MHz | 2,600MHz | 2,600MHz | 2,300MHz | 2,300MHz | 2,300MHz | 2,300MHz | 2,200MHz | 2,200MHz | 2,200MHz | 2,200MHz |
可见,活跃 core 数越多,最大 Turbo Boost 频率就越低。这是为了不让 CPU 过热。暂时忽略表格中的Mode 吧。
下面的图比较形象说明:

From 这里
超线程
Intel 官方 Hyper-Threading Technology 介绍:
Hyper-Threading Technology that allows an execution processor IA core to function as two logical processors. While some execution resources such as caches, execution units, and buses are shared, each logical processor has its own architectural state with its own set of
general-purpose registersandcontrol registers.该技术允许一个物理处理器内核在操作系统调度器层面上充当两个逻辑处理器。 虽然一些执行资源,如缓存、执行单元和总线是共享的,但每个逻辑处理器都有自己的架构状态,有自己的一组“通用寄存器”和“控制寄存器”。
需要注意,有资源的共享,意味着,有“锁”和有“锁争用”的不确定性。
Hyper-Threading: Squeezing Bubbles Out of the Processor’s Pipeline(从处理器的管道中挤出气泡) 这是我觉得把超线程说得最接地气的文章,以下是摘录部分内容:
回顾一下历史:
单处理器架构

在上图中,不同颜色表示不同进程/线程。RAM 中的每个进程都有不同的颜色。您可以看到一次只能在这个单线程 CPU 上执行一个进程。只有红色进程正在执行,其余进程必须等待轮到它们才能在 CPU 上执行。
CPU 也用其内部组件:
Front End,主要用于指令的获取和预处理。其中又可以细分为不同单元。Execute Core,主要的计算模块。其中又可以细分为不同单元。
您还应该注意到,Execution Core中的红色框(单元)周围是白色框(单元)。这些白框代表管道气泡,它们错失了在该管道阶段可能已经完成一些少量工作的机会。 CPU 的前端也有类似的白框,它代表 CPU 每个时钟周期执行 4 条指令的能力,但作为单线程处理器,在这个例子中它永远不会达到这个限制。
进程愉快地执行,直到它的时间片完成,此时处理器必须执行上下文切换,将进程的上下文保存到内存并强制程序退出执行。进程的上下文是关于该进程的一组元数据,包括它执行了多少、执行了多长时间、寄存器中的值等。进程已知或在执行期间创建的任何内容都将存储到下一个它可以被存储在处理器上执行。通过保存进程的上下文,当 CPU 下次运行该进程时,它对进程来说就好像它一直在运行而没有中断。
对称多处理器(SMP)
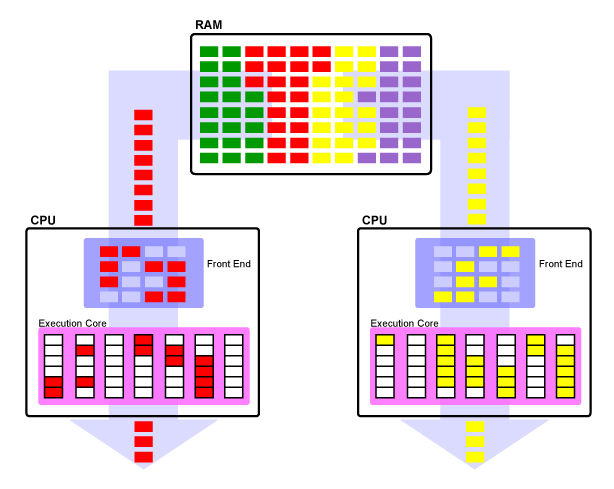
代价高昂的上下文切换问题的一种解决方案是每个处理器拥有多个内核。这允许执行两个或更多线程,每个内核上一个意味着所需的上下文切换数量大约是单线程 CPU 的一半。这被称为对称多处理 (SMP),并且已成为处理器中非常常见的布置。 需要注意的一点是,每个程序都可以由多个线程组成。当一个程序被分解成多个线程时,如果这些线程是相互独立的,那么同一个程序的多个线程可能同时在多个CPU上执行。
超线程(SMT/并行多线程/HT)
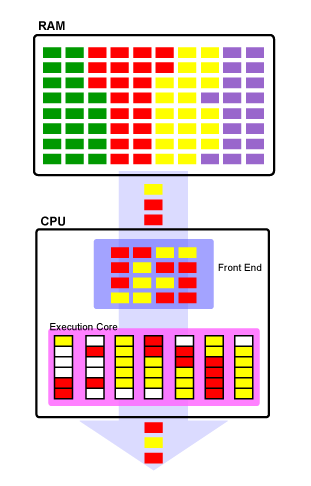
自 2002 年以来,同步多线程 (SMT) 或超线程一直是英特尔处理器(如 Pentium 4)中使用的一个概念。它通过允许每个内核执行多个线程来帮助显着减少浪费的流水线阶段的数量。操作系统调度器把每一个物理核心当作两个“逻辑”处理器来调度线程。
实现这一点的方法是在物理 Core 中重复加入两个用于存储状态的 CPU 组件(如通用寄存器)。即允许两个线程各有自己的寄存器,但它仍然具有相同数量的执行资源(Execution Resources)。这意味着当一个进程因等待内存访问或分支确认而抽风(stalled)时,另一个进程可能正在使用未使用的执行资源,而对于非超线程 CPU,这些资源将闲置。值得注意的是,这种技术的成本相当小,但它对多线程程序的呑吐量有明显提升(注意,不是速度提升,也不是 Latency 减少)。
同样,在上图中,您可以看到超线程 CPU 处理数据的示例。它同时执行来自红色和黄色进程的数据,并尽可能地填充管道阶段,以允许所有执行阶段尽可能频繁地忙碌。您会注意到前端(CPU 指令)和管道本身的气泡要少得多。虽然在此示例中完成的工作量与单线程 SMP 设计完全相同,但浪费的流水线阶段要少得多,并且使用的资源大约有一半,因为仍然只有一组执行资源。
SMT 最酷的部分是操作系统不需要特殊的逻辑来使用 SMT。只要操作系统能够与 SMP 处理器一起工作,它就会将具有超线程能力的 CPU 识别为物理处理器数量的两倍。例如,如果您有幸拥有一个六核 Intel i7 处理器,您的计算机将读取十二个逻辑处理器以供使用。
如果上面的色块图让你迷惑,那么下面这个简化图应该比较好理解:
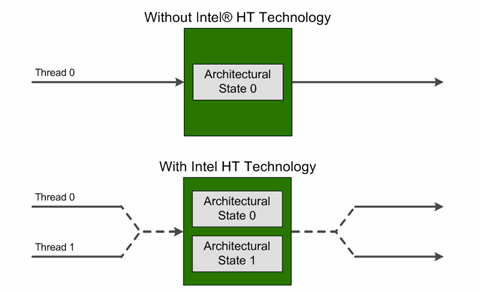
from Will Hyper-Threading Improve Processing Performance?
超线程与 Turbo Boost 的相关性
from Intel Hyper-Threading Technology:
Processors with both
Intel Hyper-ThreadingTechnology andIntel Turbo BoostTechnology deliver better performance and can complete tasks more quickly. The combination of technologies enables simultaneous processing of multiple threads, dynamically adapts to the workload, and automatically disables inactive cores. This increases processor frequency on the busy cores, giving an even greater performance boost for threaded applications.同时采用“超线程”技术和“睿频加速”技术的处理器可提供更好的性能,并能更快地完成任务。 技术组合可以同时处理多个线程,动态适应工作负载,自动禁用非活动核心。 这增加了繁忙核心上的处理器频率,从而为线程应用程序提供了更大的性能提升。
Measuring Hyper-Threading and Turbo Boost 一文说明了开启超线程,且关闭 Turbo Boost 情况 下,HTTP 请求的延迟增加的情况(不过,其使用的是 AMD CPU。AMD 对应 Intel Turbo Boost 的技术叫:Core Performance Boost(CPB)):
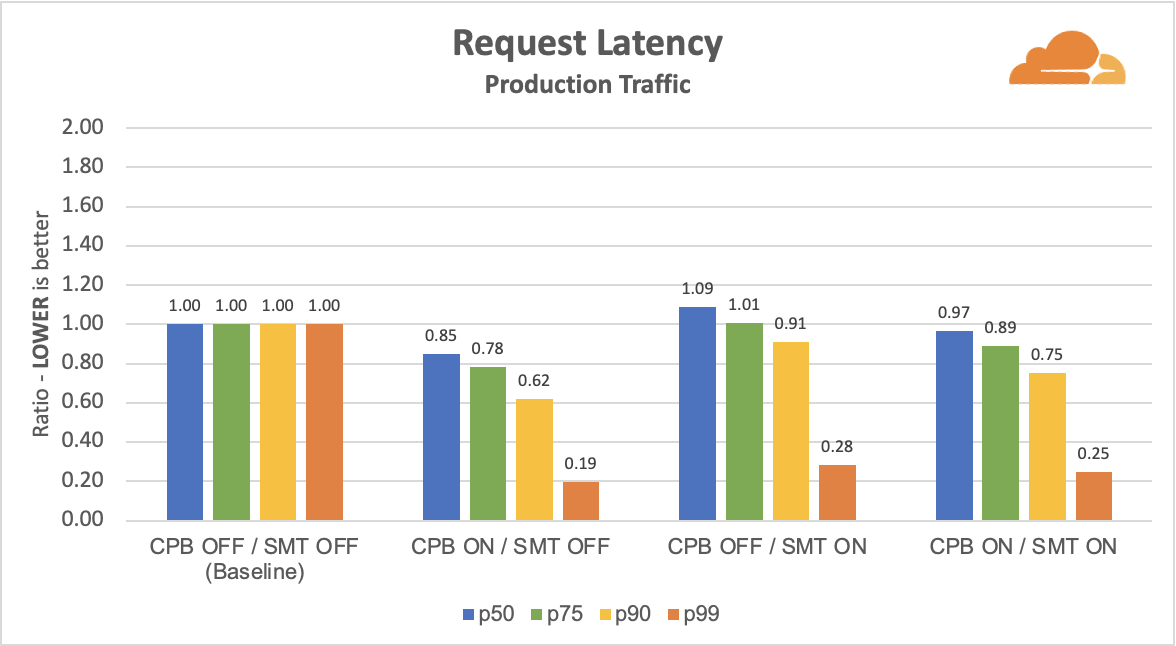
超线程的负面
了解我的写作风格的同学也知道,我时常关注技术的负面影响。下面说说超线程的负面。
超线程共享了 core 的一些资源,意味着,有硬件上的“锁”和有“锁争用”的不确定性。在数据上,也有两个线程相互干扰的可能。
缓存抖动(cache thrashing)
They also state that while there(SMT) will be greater efficiency in the pipeline over the SMP processor, they have found that an SMT processor will have “42% more cache thrashing” over the SMP design.
他们还指出,虽然 SMT 的处理器的流水线效率比 SMP 更高,但他们发现 SMT 处理器比 SMP多出 42% 的缓存抖动。
Hyperthreading, L1/L2 caching, cache busting, thread trashing, and priority bumping! 一个节目讨论了:超线程、L1/L2 缓存、缓存破坏、优先级碰撞!
Performance at its (CPU-) Core 一文中,从CPU架构说明了其中的原理:
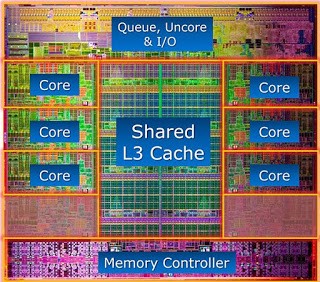
CPU 缓存分级为:
-
L1I:用于指令的小型、非常快速的缓存。Core间不共享。
-
L1D:一个小而快的数据缓存。Core间不共享。
-
L2:用于数据和指令的更大缓存。 此缓存有时在 Core 之间共享,但通常不共享。
-
L3:所有Core共享的大型缓存。 它可以轻松占据整个处理器裸片的 1/3,以提供最佳命中率(见上图)。
Linux 在为线程选择执行 Core 时,也会考虑到上面 Cache 的复用优化。
而同一 物理 Core 上的两个逻辑 Core 可能会相互干扰 Cache。试想如果两个不同应用执行于同一物理 Core,干扰将放大。
Hyper-Threaded Cache Coherent Raycasting 一文深入讨论了这个问题。
如何测量超线程的影响
Measuring Intel Hyper-Thread Overhead
核心和线程 CPI:CPI 代表每条指令的周期数。这是执行给定指令集的平均时间。 CPI 指示代码中的指令级并行性。 CPI 也可用于估计缓存行因 cpu 缓存中的陈旧数据而失效时的内存获取延迟。例如:基于 Nehalem 内核的 Intel 处理器每个时钟可以执行 4 条指令,即相当于 CPI 0.25。由于缓存未命中和分支错误预测,实际应用程序的平均 CPI 为 1.0 或 2.0。
要捕获核心 CPI,请禁用 HT 并测量 CPI。由于核心专用于单线程,它会给你核心 CPI。
现在启用 HT。由于两个线程共享内核,它们可能执行不同数量的指令和 CPI。让我们假设在一个采样周期内,共享一个内核的两个线程使用了 100 万个内核周期。在此期间,Thread-1 执行了 750k 条指令,Thread-2 执行了 500k 条指令。在这种情况下,Thread-1 CPI:1.33、Thread-2 CPI:2.0 和 Core CPI:0.80(100 万个周期/750+500 条指令)。
Linux 内核
被误解的 CPU 利用率(Utilization)
什么是 CPU 利用率
首先看看什么是 CPU 利用率(Utilization)。我在写这编文章前,以为自己见识了近30年的编程,这东西应该再了解不过。但性能领域有其它领域一样,有的概念我们天天使用,名字熟识不过了,却很少有人深究其本质来源和原理。
CPU time accounting- Linux on System z Performance Evaluation - IBM
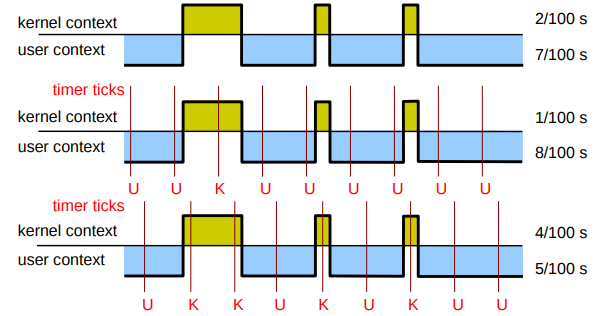
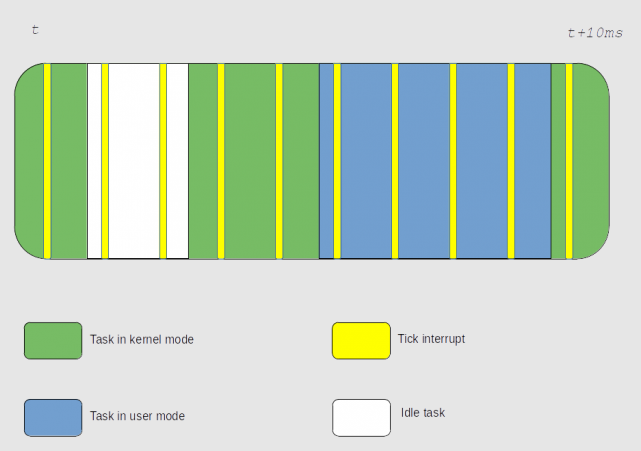
Linux 在每个 CPU 上高频周期 Timer 中断执行中的线程。在中断时采样识别被中断的线程,并把本周期的时间片都计入被中断线程的CPU使用账中。
CPU Isolation – Introduction – by SUSE Labs
如果 CPU 利用率(Utilization) 是你的最重要性能指标,那么不好意思。你可能有点点 Out 了,见以下文章:
CPU利用率的分类
UNDERSTANDING CPU USAGE IN LINUX - opsdash
System: The CPU is running kernel code. This includes device drivers and kernel modules.
User: The CPU is running code in user-mode. This includes your application code. Note that if an application tries to read from disk or write to network, it actually goes to sleep while the kernel performs that work, and wakes up the application again.
I/O Wait: Sometimes the CPU has only one thing to do – wait for the results of a disk/network read/write. This isn’t as uncommon as you’d think. A file server for example would nearly spend all it’s life waiting for disk reads and network writes to complete. I/O Wait is when the CPU is waiting for an I/O operation to complete, and the CPU can’t be used for anything else.
Steal: When running in a virtualized environment, the hypervisor may “steal” cycles that are meant for your CPUs and give them to another, for various reasons. This time is accounted for as steal.
Idle: And when there is really nothing the kernel can do, it just as to waste away this slice of time. Technically, when the runnable queue is empty and there are no I/O operations going on, the CPU usage is marked as idle.
And there are a couple of other types too, which you probably won’t see much of:
- IRQ and SoftIRQ: The kernel is servicing interrupt requests (IRQs).
错误(或最少是误导)的 CPU 利用率
CPU Utilization is Wrong - Brendan Gregg
您可能认为 90% 的 CPU 利用率意味着:
而可能的真相是:


Utilization is Virtually Useless as a Metric! - Adrian Cockcroft - Netflix Inc.
大部分人理解的 CPU 利用率和可用率是这样的:
但实际计算的方式是这样的:
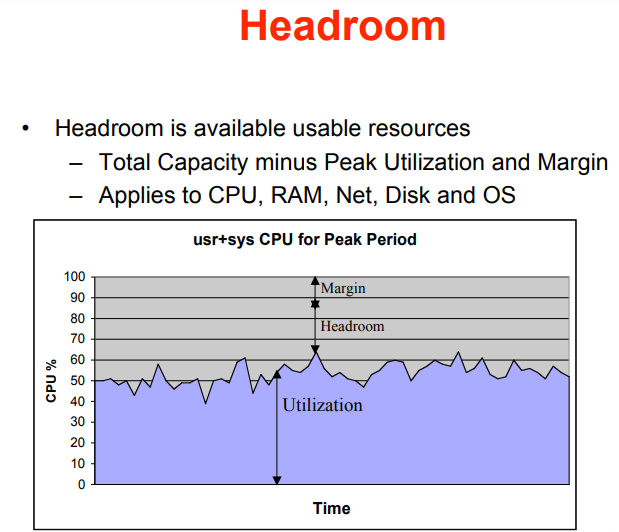
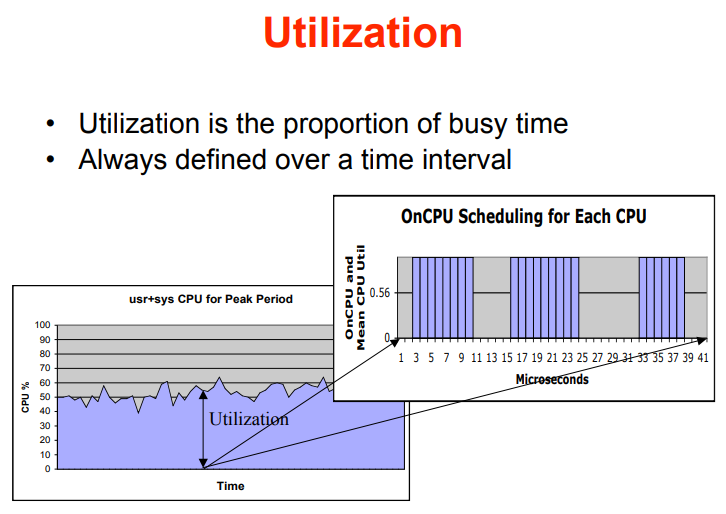
超线程下 CPU 利用率非线性
而超线程下的应用 CPU 利用率的非线性,可能有更多的问题:
Measuring CPU Time from Hyper-Threading Enabled Intel ® Processors - Computer Measurement Group 中做了个实验。是 2004 年的实验,不过还是有一定参考意义的。细节数据我不贴出来了,有兴趣的看看原文。说说总结:
- 相同的算法程序。关闭超线,各种并发压力下,CPU 用时(sys time + user time,注意不是实际用时(real time) )相同
- 相同的算法程序。开启超线,各种并发压力下,CPU 用时( sys time + user time ),在程序线程数未超过物理 Core 数前,结果和上面一样 。
- 相同的算法程序。开启超线,各种并发压力下,CPU 用时( sys time + user time ),在程序线程数超过物理 Core 数后,会随着逻辑 CPU 的用量增加而增加。
CPU utilization of multi-threaded architectures explained - Oracle Solaris Blog:
资源共享有什么好处?
资源共享可以通过保持核心的处理单元繁忙来提高整体吞吐量和效率。 例如,超线程可以减少或隐藏内存访问的停顿(缓存未命中)。 在从主内存中获取数据时不会浪费许多周期,而是暂停当前线程并恢复下一个可运行线程并继续执行。有什么缺点?
工具报告的 CPU 时间测量指标 (sys/usr/idle) 并未反映硬件线程之间资源共享的副作用。
无法正确测量空闲并推断可用计算资源。Idle 不再表示 CPU 还能完成多少工作:
例如:
假设 1 个 CPU 内核有 4 个线程。 目前,有 2 个(单线程)进程计划在此内核上运行,这 2 个进程已经使内核的所有可用共享计算资源(ALU、FPU、缓存、内存带宽等)饱和。 常用的性能工具仍会报告(至少)50% 的空闲,因为 2 个逻辑处理器(硬件线程)看起来完全空闲。
HyperThreading and CPU usage - Intel® oneAPI Math Kernel Library:
问题是通过正在使用的 “
逻辑处理器” 的数量来定义 “CPU 利用率”。 每个 “物理核心” 使用一个 “逻辑处理器” 可以被认为是 100% 的 “CPU 利用率”,但通常报告为 50% 的 “CPU 利用率”。 这让很多人感到困惑。 没有明确的 “正确答案” —— 尤其是有两种情况都可能达到“50% CPU 利用率”:
在每个 “物理内核”上使用一个“逻辑处理器”
在一半“物理内核”上使用两个“逻辑处理器”。
后者通常不是您想要做的,但是对于“CPU 利用率”的单一指标是无法区分的。
Hyper-threading -How does it double CPU throughput?:
对于 12 core 即 24 个超线程的 CPU 的实验结果:
X 轴是线程数,Y 轴是 TPS。
- 您看不到系统实际利用率的真实情况——如果 CPU 图表显示利用率为 30%,那么您的系统很可能已经利用率为 60%。
- 超过 60% 的物理利用率,您的请求的执行速度将被故意限制以提供更高的系统吞吐量。
因此,如果您正在优化更高的吞吐量——那可能没问题。 但是,如果您正在优化响应时间,那么您可以考虑在关闭 HT 的情况下运行。
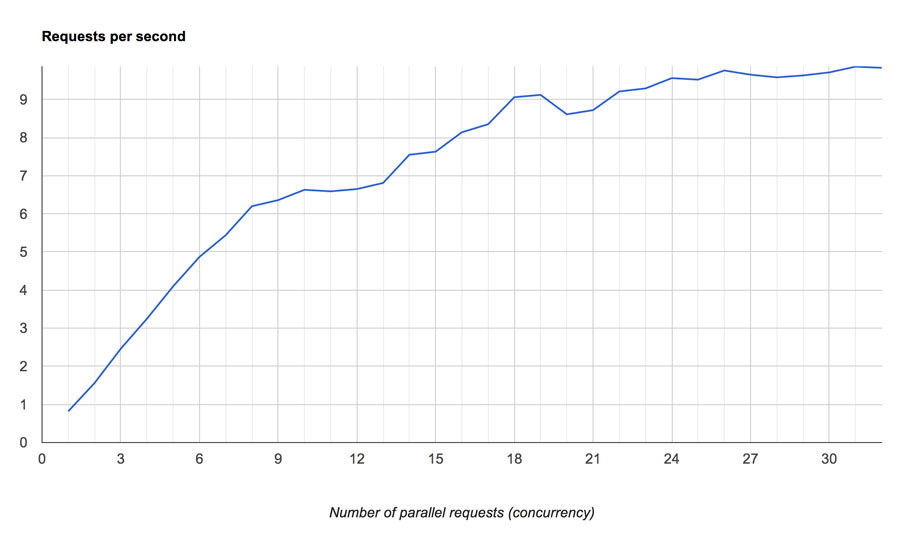
Monitoring CPU Utilization Under Hyper-threading:
我拥有的最佳情况测试测量表明,每个 超线程的平均繁忙度不能超过 75%,或者根据操作系统的预期总容量 200% 的 150%。 我之前提到的“缺失”的 50% 容量是一种错觉。 英特尔声称,对于一般应用程序,可以预期 120% 到 130% 的范围内。
动态调频下 CPU 利用率非线性
上面提到的动态调频技术,同样影响 CPU 利用率:
- Speed Shift Technology
- Turbo Boost Technology
Linux 调度器对超线程的优化
上面聊了很多硬件问题。回到操作系统上。一个能直接想到的问题是:Linux 会根据超线程和物理 Core 的关系,去优化线程的调度吗?
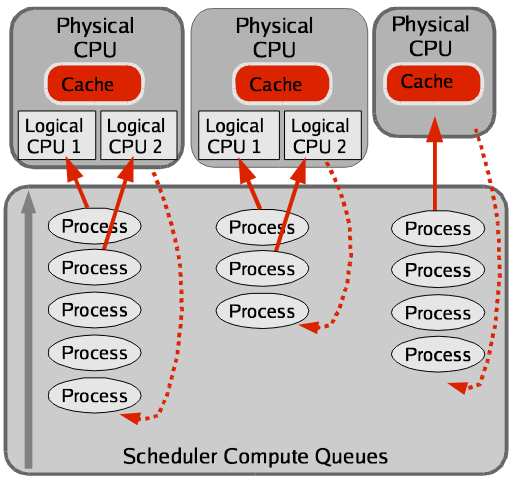
Linux scheduler is aware of HyperThreading
超线程支持确保调度程序可以区分物理 CPU 和逻辑(超线程)CPU。 调度程序计算队列是针对每个物理 CPU 实现的,而不是针对每个逻辑 CPU(如之前的情况)。 这导致进程在物理 CPU 上均匀分布,从而最大限度地利用 CPU 缓存和指令缓冲区等资源。
Linux 观察 CPU 性能管理策略与性能状态
这个问题留给下一 part 2 来讨论,内容预告:
- CPU 性能与电源策略
- CPU 工作频率与
p-state的观察 - Turbo Boost 的配置与观察
Cloud
云容器化部分暂时未深入研究,不过发现一些有趣的参考资源:
- Container Bare Metal for 2nd Generation and 3rd Generation Intel Xeon Scalable Processor - REFERENCE ARCHITECTURE RELEASE V21.08
- Container Bare Metal for 2nd Generation and 3rd Generation Intel® Xeon® Scalable Processor and Intel® Xeon® D Processor Reference Architecture User Guide Release V22.01
附录
C-State
Unlike the P-States, which are designed to optimize power consumption during code execution, C-States are used to optimize or reduce power consumption in idle mode (i. e. when no code is executed).
- https://www.intel.com/content/www/us/en/develop/documentation/vtune-help/top/reference/energy-analysis-metrics-reference/c-state.html
- https://www.thomas-krenn.com/en/wiki/Processor_P-states_and_C-states
- https://www.technikaffe.de/anleitung-32-c_states_p_states_s_states__energieverwaltung_erklaert