
This article is an excerpt from some recent updates to my book, Envoy Proxy Insider, covering the Event-Driven Framework and the Threading Model. These are considered the foundational core of Envoy Proxy. Most people think of Envoy as a proxy that primarily forwards requests with custom logic. This is correct. However, like other middleware with high-load, low-latency requirements, its design must consider load scheduling and flow control. A good scheduling design must balance throughput, response time, and resource consumption (footprint). This article primarily discusses topics related to events, scheduling, and multi-threaded coordination.
Event-Driven Framework
Design
Most people think of Envoy as a proxy that primarily forwards requests with custom logic. This is correct. However, like other middleware with high-load, low-latency requirements, its design must consider load scheduling and flow control. A good scheduling design must balance throughput, response time, and resource consumption (footprint).

Figure: Event-Driven Framework Design
Open with Draw.io
{kind=link}
-
Dispatcher thread event loop. The
Dispatcher Threadwaits for events (epoll wait) and processes them after a timeout or when an event occurs. -
The following events can wake up the epoll wait:
- Receiving an inter-thread post callback message. This is mainly used for updating Thread Local Storage (TLS) data, such as Cluster/Stats information.
- The Dispatcher handles inter-thread events.
- Timer timeout events.
- File/socket/inotify events.
- Internal active events. These are triggered when another internal thread, or the dispatcher thread itself, explicitly calls a function to trigger an event.
- Receiving an inter-thread post callback message. This is mainly used for updating Thread Local Storage (TLS) data, such as Cluster/Stats information.
-
Process events.
A single event processing loop consists of the three steps above. The completion of these three steps is called an event loop, or sometimes an event loop iteration.
Implementation
The section above described the low-level process of event handling at the kernel syscall level. The following section explains how events are abstracted and encapsulated at the Envoy code level.
Envoy uses libevent, an event library written in C, and builds C++ OOP-style wrappers on top of it.

Figure: Envoy’s Abstract Event Encapsulation Model
Open with Draw.io
{kind=link}
How can you quickly understand the core logic in a project that heavily (or even excessively) uses OOP encapsulation and design patterns, without getting lost in a sea of source code? The answer is to find the main thread of logic. For Envoy’s event handling, the main thread is, of course, the libevent objects:
libevent::event_baselibevent::event
If you are not yet familiar with libevent, you can refer to the ‘Core Concepts of libevent’ section in this book.
libevent::eventis encapsulated in theImplBaseobject.libevent::event_baseis contained withinLibeventScheduler<-DispatcherImpl<-WorkerImpl<-ThreadImplPosix.
Then, different types of libevent::event are encapsulated into different ImplBase subclasses:
TimerImpl- Used for all timer-based functionalities, such as connection timeouts, idle timeouts, etc.SchedulableCallbackImpl- By design, under high load, Envoy needs to balance the response time and throughput of event handling. To balance the workload of eachevent loopand avoid a single loop taking too long and affecting the responsiveness of other pending events, some internally-initiated or timer-initiated processes can be scheduled to complete at the end of the currentevent loopor be “deferred” to the next one.SchedulableCallbackImplencapsulates this type of schedulable task. Use cases include: thread callback posts, request retries, etc.FileEventImpl- For file/socket events.
The diagram above provides more details, so I won’t elaborate further.
Threading Model
If you were given an open-source middleware to analyze its implementation, where would you start? The answers might be:
- Source code modules
- Abstract concepts and design patterns
- Threads
For modern open-source middleware, I believe the thread/process model is almost the most important aspect. This is because modern middleware generally uses multiple processes or threads to fully utilize hardware resources. No matter how well-encapsulated the abstractions are or how elegantly the design patterns are applied, the program ultimately runs as threads on the CPU. How these multiple threads are divided by function and how they communicate and synchronize with each other are the difficult and critical points.
Simply put, Envoy uses a non-blocking + Event-Driven + Multi-Worker-Thread design pattern. In the history of software design, there are many names for similar design patterns, such as:
This section assumes the reader is already familiar with Envoy’s event-driven model. If not, you can read the {doc}
/arch/event-driven/event-drivensection of this book.
The content of this section references: Envoy threading model - Matt Klein
Unlike Node.JS’s single-threaded model, Envoy supports multiple Worker Threads, each running its own independent event loop, to take full advantage of multi-core CPUs. However, this design comes at a cost, as the multiple worker threads and the main thread are not completely independent. They need to share some data, such as:
- Upstream Cluster endpoints, health status, etc.
- Various monitoring and statistical metrics.
Thread Overview
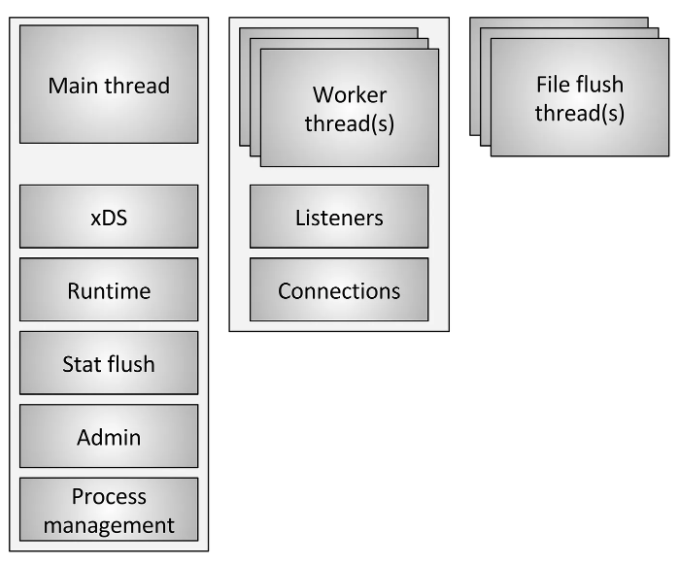
Figure : Threading overview
Source: Envoy threading model - Matt Klein
Envoy uses several different types of threads, as shown in the figure above. The main ones are described below:
-
main: This thread is responsible for server startup and shutdown, all xDS API handling (including DNS, health checking, and general cluster management), runtime, stats flushing, admin, and general process management (signals, hot restart, etc.). Everything that happens on this thread is asynchronous and “non-blocking.” In general, the main thread coordinates all critical functions that do not require a large amount of CPU to complete. This allows most of the management code to be written as if it were single-threaded.
-
worker: By default, Envoy spawns one worker thread for each hardware thread in the system. (This can be controlled via the –concurrency option). Each worker thread runs a “non-blocking” event loop and is responsible for listening on each listener, accepting new connections, instantiating a filter stack for the connection, and handling all I/O throughout the connection’s lifecycle. This allows most of the connection handling code to be written as if it were single-threaded.
Thread Local
Because Envoy separates the responsibilities of the main thread from those of the worker threads, complex processing needs to be done on the main thread and then made available to each worker thread in a highly concurrent manner. This section will provide a high-level overview of Envoy’s Thread Local Storage (TLS) system. Later, I will explain how this system is used to handle cluster management.
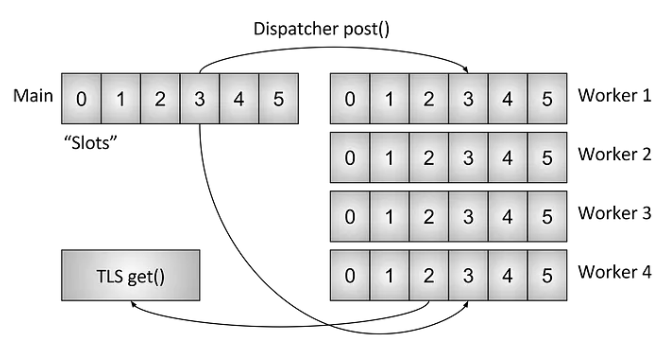
Source: Envoy threading model - Matt Klein
Figure : Thread Local Storage (TLS) system
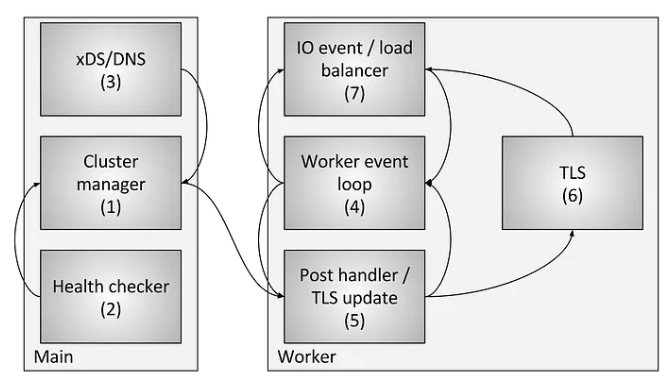
Source: Envoy threading model - Matt Klein
Figure : Cluster manager threading
If shared data were accessed using locks for both reads and writes, concurrency would inevitably decrease. Therefore, after analyzing that the real-time consistency requirements for data synchronization updates were not strict, the author of Envoy referenced the Linux kernel’s read-copy-update (RCU) design pattern and implemented a Thread Local data synchronization mechanism. At the low level, it is implemented based on C++11’s thread_local feature and libevent’s libevent::event_active(&raw_event_, EV_TIMEOUT, 0).
The diagram below, based on Envoy threading model - Matt Klein, uses the Cluster Manager as an example to illustrate how Envoy uses the Thread Local mechanism at the source code level to share data between threads.

Figure: ThreadLocal Classes
Open with Draw.io
{kind=link}
The diagram above can be summarized as follows:
- The main thread initializes
ThreadLocal::InstanceImpl, and eachDispatcheris registered withThreadLocal::InstanceImpl. - The main thread notifies all worker threads to create a local
ThreadLocalClusterManagerImpl. - When the main thread detects that a Cluster has been deleted, it notifies the
ThreadLocalClusterManagerImplon each worker thread to delete that Cluster. - When a
TCPProxyon a worker thread attempts to connect to anOnDemand Cluster(an unknown cluster), it retrieves the thread-localThreadLocalClusterManagerImpl.