![]()
[TOC]
概述
Java 支持好几种文件读取方法,本文要说的是小众的 mmap(MappedByteBuffer) 以及它与 Safepoint、JVM 服务卡顿之间的关系。本文尝试用 eBPF 等分析方法,去证明具体环境下,问题的存在与否。
审误和发布本文时,我才是二阳后活过来数小时而已,写了数周的文章实在不想再拖延发布了。如文章有错漏,还请多多包涵和指正。
引
Java 服务卡顿,是 Java 世界永恒的话题之王。想到 Java 卡顿,大部分人的第一反应是以下关键词:
- GC
- Safepoint / Stop the world(STW)
而说访问 mmap(MappedByteBuffer) 导致 Java 卡顿可能是个小众话题。但如果你了解了一些基于 Java 的重 IO 的开源项目后,就会发现,这其实不是个小众话题。如曾经大热的 NoSQL 数据库 [Cassandra 默认就是重度使用 mmap 去读取数据文件和写 commit log 的](Cassandra 默认就是重度使用 mmap 去读取数据文件和写 commit log 的)。
基本原理
JVM 写 GC 日志时机分析
Safepoint
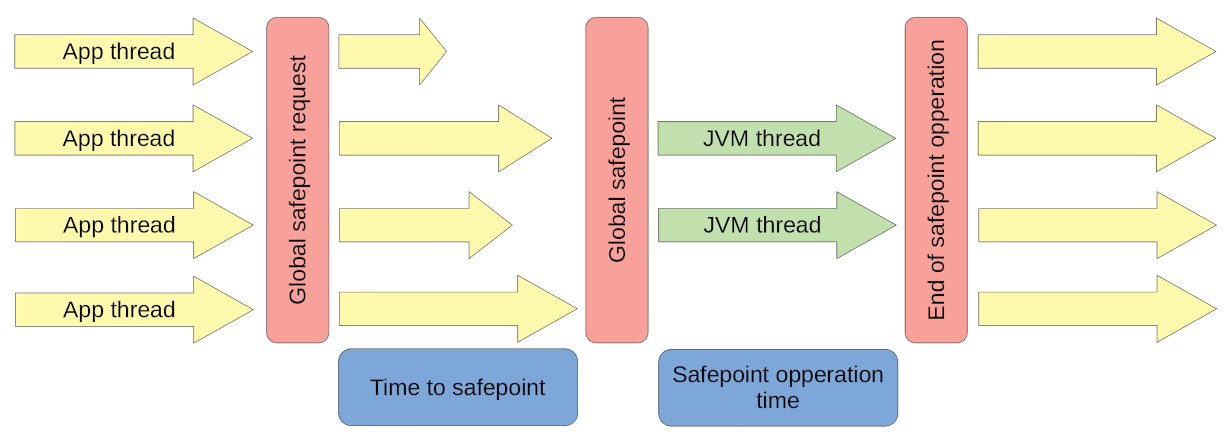
[From https://krzysztofslusarski.github.io/2022/12/12/async-manual.html#tts]
上图大概说明了 safepoint 的主要流程。有兴趣同学可以看看上面链接,或搜索一下,网上很多好文章说明过了。我就不搬门弄斧了。
一点需要注意的是,safepoint STOP THE WORLD(STW) 的使用者不只有 GC。还有其它。
这里只简单说明一下(我不是 JVM 专家,所以请谨慎使用以下观点):
-
Global safepoint request
1.1 有一个线程提出了进入 safepoint 的请求,其中带上
safepoint operation参数,参数其实是 STOP THE WORLD(STW) 后要执行的 Callback 操作 。可能是分配内存不足,触发 GC。也可能是其它原因。1.2 一个叫 “
VM Thread” 的线程在收到 safepoint request 后,修改一个 JVM 全局的safepoint flag为 true(这里只为简单说明,如果你是行家,那么这个 flag 其实是操作系统的内存缺页标识) 。1.3 然后这个 “VM Thread” 就开始等待其它应用线程(App thread) 到达(进入) safepoint 。
1.4 其它应用线程(App thread)其实会高频检查这个 safepoint flag ,当发现为 true 时,就到达(进入) safepoint 状态。
源码链接 SafepointSynchronize::begin()
本文主要关注这里的 “等待其它应用线程(App thread) 到达(进入) safepoint”。
-
Global safepoint
当 “
VM Thread” 发现所有 App thread 都到达 safepoint (真实的 STW 的开始) 。就开始执行safepoint operation。GC 操作是safepoint operation其中一种可能类型。 -
End of safepoint operation
safepoint operation执行完毕, “VM Thread” 结束 STW 。
症状
假设已经加入 java 命令参数:
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCDetails
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount=1
-XX:+SafepointTimeout
-XX:SafepointTimeoutDelay=<ms before timeout log is printed>
GC log:
# 大部分时间,花在 Global safepoint request 与 Global safepoint 这间的“等待其它应用线程(App thread) 到达(进入) safepoint”
2023-09-07T13:19:50.029+0000: 58103.440: Total time for which application threads were stopped: 3.4971808 seconds, Stopping threads took: 3.3050644 seconds
或 safepoint log:
[safepoint ] Application time: 0.1950250 seconds
[safepoint ] Entering safepoint region: RevokeBias
[safepoint ] Leaving safepoint region
[safepoint ] Total time for which application threads were stopped: 0.0003424 seconds, Stopping threads took: 0.0000491 seconds
///////
# SafepointSynchronize::begin: Timeout detected:
# SafepointSynchronize::begin: Timed out while spinning to reach a
# safepoint.
# SafepointSynchronize::begin: Threads which did not reach the
# safepoint:
# "SharedPool-Worker-5" #468 daemon prio=5 os_prio=0
# tid=0x00007f8785bb1f30 nid=0x4e14 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
>> >
# SafepointSynchronize::begin: (End of list)
vmop [threads: total initially_running
wait_to_block] [time: spin block sync cleanup vmop]
page_trap_count
58099.941: G1IncCollectionPause [ 447 1
1 ] [ 3304 0 3305 1 190 ] 1
>>
这个问题已经在 Cassandra 界有了个朵:
- JVM safepoints, mmap, and slow disks 或这里
- Use of MappedByteBuffer could cause long STW due to TTSP (time to safepoint)
- Long unexplained time-to-safepoint (TTSP) in the JVM
那么问题来了,怎么证明你的环境的 java 应用存在或不存在这个问题?
诊断
环境准备
IO 卡顿的模拟方法见 [Linux 如何模拟 IO 卡顿] 一节。
生成测试文件:
|
|
测试的目标 java 程序
|
|
程序的主要逻辑是在 TestGCLog 线程中触发 GC 。在 main 线程中随机访问 mmap 映射到内存中的文件,以触发 page fault 和 IO 。
bpftrace 程序
|
|
执行
|
|
|
|
跟踪输出:
37507 568704 java filemap_fault()
37507 568704 java kretfunc:ext4_mpage_readpages 1026187264 mapped.file
38521 568704 java kretfunc:filemap_fault()
38531 568704 java filemap_fault()
38531 568704 java kretfunc:ext4_mpage_readpages 116322304 mapped.file
39549 568704 java kretfunc:filemap_fault()
39569 568704 java filemap_fault()
39569 568704 java kretfunc:ext4_mpage_readpages 960757760 mapped.file
40601 568704 java kretfunc:filemap_fault()
40632 568704 java filemap_fault() <--- Page Fault START
40632 568704 java kretfunc:ext4_mpage_readpages 484405248 mapped.file
41386 568719 VM Thread SafepointSynchronize::begin <-- waiting for safepoint reach START
41657 568704 java kretfunc:filemap_fault() <-- Page Fault END
41658 568719 VM Thread RuntimeService::record_safepoint_synchronized <-- waiting for safepoint reach END
41658 568719 VM Thread SafepointSynchronize::end
===========
41669 568704 java filemap_fault()
41669 568704 java kretfunc:ext4_mpage_readpages 43298816 mapped.file
42681 568704 java kretfunc:filemap_fault()
42691 568704 java filemap_fault()
42691 568704 java kretfunc:ext4_mpage_readpages 828358656 mapped.file
43709 568704 java kretfunc:filemap_fault()
43719 568704 java filemap_fault()
43719 568704 java kretfunc:ext4_mpage_readpages 191881216 mapped.file
44732 568704 java kretfunc:filemap_fault()
44743 568704 java filemap_fault() <--- Page Fault START
44743 568704 java kretfunc:ext4_mpage_readpages 905154560 mapped.file
45574 568719 VM Thread SafepointSynchronize::begin <-- waiting for safepoint reach START
45753 568704 java kretfunc:filemap_fault()) <-- Page Fault END
45754 568719 VM Thread RuntimeService::record_safepoint_synchronized <-- waiting for safepoint reach END
45755 568719 VM Thread SafepointSynchronize::end
可见隐患的确存在。只是视环境条件是否满足,爆不爆发而已。
如果用回没有 IO 卡顿的盘试试:
|
|
问题不存在。
云原生下可能加剧的问题
-
worker node 共享内存 或 container limit 内存后,Direct Page Reclaim
在云环境下,一台机器可能运行很多 container 。有的 container 是高 IO 的应用,如写日志,这些都会占用 page cache 和对共享的 disk 产生争用压力 。 整机的内存不足,或者是 container 本身的内存不足,都可能触发 Direct Page Reclaim
-
worker node 共享本地磁盘 IO 争用
-
Ceph 等 PV 网络盘稳定性远不如本地盘,带宽与 latency 相对不稳定。
如以下一个配置,多个 container 可能共享了 emptyDir 用的本地盘。然后在 IO 争用时,写 GC 日志就可能出现 STW 下的高 latency ,直接导致服务 API latency 超时。
|
|
结语
后面,我会写另外两编文章:《eBPF 求证坊间传闻:Java GC 日志可导致整个 JVM 服务卡顿?》、《如何测量 进程级别的 IO 延迟》
附录
Linux 如何模拟 IO 卡顿
网上能搜索到的模拟 IO 卡顿大概有两个方法:
- device mapper delay 法
- systemtap 注入延迟法
本文用的是 device mapper delay 法。device 本身带了一个 delay。
|
|
另外如果 debug 需要,可以挂起 device ,直接让 mapper device 的所有 IO 操作进程挂起(uninterruptable_sleep):
|
|
Ubuntu 下的 BPF 跟踪堆栈由于 -fno-omit-frame-pointer 的 glibc 缺失的问题
sudo apt install libc6-prof
env LD_LIBRARY_PATH=/lib/libc6-prof/x86_64-linux-gnu /usr/lib/jvm/java-17-openjdk-amd64/bin/java ...
TL;DR :
https://bugs.launchpad.net/ubuntu/+source/glibc/+bug/1908307