![]()
[TOC]
概述
实现世界的 Java 应用,都会记录 GC 日志。但不是所有人都知道小小的日志可能导致整个 JVM 服务卡顿。本文尝试用 eBPF 等分析方法,去证明具体环境下,问题的存在与否。
审误和发布本文时,我才是二阳后活过来数小时而已,写了数周的文章实在不想再拖延发布了。如文章有错漏,还请多多包涵和指正。
引
Java 服务卡顿,是 Java 世界永恒的话题之王。想到 Java 卡顿,大部分人的第一反应是以下关键词:
- GC
- Stop the world(STW)
而写 GC 日志导致 Java 卡顿可能是个小众话题。不过我的确在之前的电商公司中目睹过。那是 2017 年的 12/8 左右,还是 Java 8,当时相关的专家花了大概数周时间去论证和实验,最终开出诊断结果和药方:
- 诊断结果:写 GC 日志导致 JVM GC 卡顿
- 药方:GC 日志不落盘(写 ram disk/tmpfs),或落到独立的 disk 中。
转眼来到 2023 年,OpenJDK 21 都来了。问题还在吗?看看搜索引擎的结果:
- Eliminating Large JVM GC Pauses Caused by Background IO Traffic - 2016年 Zhenyun Zhuang@LinkedIn
- JVM性能调优–YGC - heapdump.cn
- JVM 输出 GC 日志导致 JVM 卡住,我 TM 人傻了
OpenJDK 的修正方案
这个问题是有广泛认知了,OpenJDK 也给出了解决修正:
- Buffered Logging? - rramakrishna@twitter.com
- JDK-8229517: Support for optional asynchronous/buffered logging
- JDK-8264323: Add a global option -Xlog:async for Unified Logging
- Asynchronous Logging in Corretto 17 - Xin Liu@amazon.com
遗憾的是,出于新版本与旧版本行为一致的兼容性原则,这个修正默认是关闭的,即需要加 Java 命令行参数 -Xlog:async 来手工打开异步原生线程写 GC 日志的 “功能” 。
那么问题来了,是直接加参数了事,还是求证一下,服务的卡顿来源是否真正来源于这个问题,再考虑修改参数? 当然,本文选择是后者。
基本原理
JVM 写 GC 日志时机分析
Safepoint
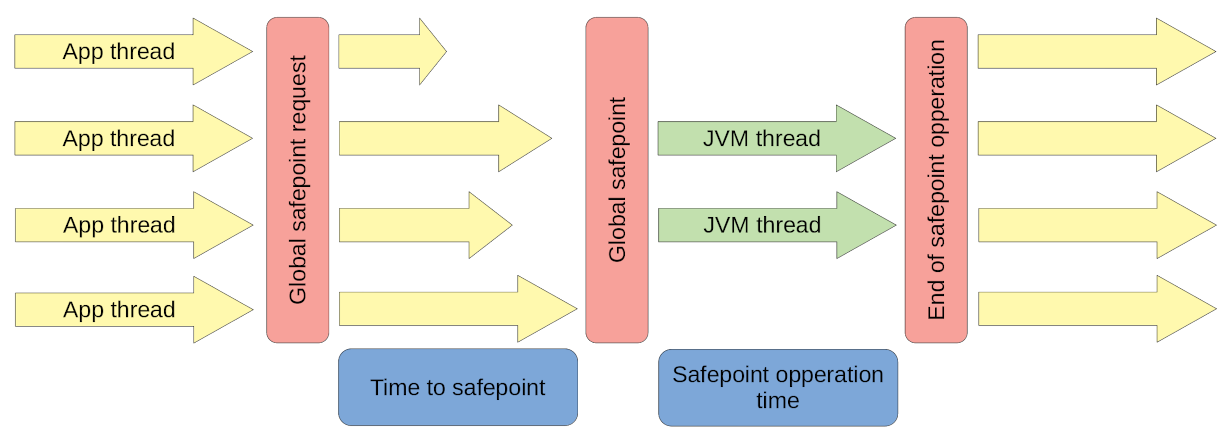
[From https://krzysztofslusarski.github.io/2022/12/12/async-manual.html#tts]
上图大概说明了 safepoint 的主要流程。有兴趣同学可以看看上面链接,或搜索一下,网上很多好文章说明过了。我就不搬门弄斧了。
一点需要注意的是,safepoint STOP THE WORLD(STW) 的使用者不只有 GC。还有其它。
这里只简单说明一下(我不是 JVM 专家,所以请谨慎使用以下观点):
-
Global safepoint request
1.1 有一个线程提出了进入 safepoint 的请求,其中带上
safepoint operation参数,参数其实是 STOP THE WORLD(STW) 后要执行的 Callback 操作 。可能是分配内存不足,触发 GC。也可能是其它原因。1.2 一个叫 “
VM Thread” 的线程在收到 safepoint request 后,修改一个 JVM 全局的safepoint flag为 true(这里只为简单说明,如果你是行家,那么这个 flag 其实是操作系统的内存缺页标识) 。1.3 然后这个 “VM Thread” 就开始等待其它应用线程(App thread) 到达(进入) safepoint 。
1.4 其它应用线程(App thread)其实会高频检查这个 safepoint flag ,当发现为 true 时,就到达(进入) safepoint 状态。
-
Global safepoint
当 “
VM Thread” 发现所有 App thread 都到达 safepoint (真实的 STW 的开始) 。就开始执行safepoint operation。本文中,当然就是GC 操作了。 -
End of safepoint operation
safepoint operation执行完毕, “VM Thread” 结束 STW 。
GC
上面关键一点是,在 STW 后,会执行 GC 操作 ,完毕后,才结束 STW。GC 操作 是会写 GC 日志的,默认会调用 write syscall 。证明见下面。
诊断
诊断 - eBPF 跟踪法
先看看 bpftrace 程序 trace-safepoint.bt :
|
|
这个程序假设你的机器上只运行了一个 java 程序,如果多个,要作点修改。
我们主要看 BPF probe 探针点:
- uprobe:SafepointSynchronize::begin()
- uprobe:RuntimeService::record_safepoint_synchronized()
- uprobe:LogFileOutput::*() : JVM 日志写文件代码
- uprobe:AsyncLogWriter::*() : JVM 日志异步化代码
- kprobe:vfs_write :内核文件写操作
- uprobe:SafepointSynchronize::end()
然后写一个简单的 Java 程序, TestGCLog.java :
|
|
执行 java 程序和 bpftrace:
|
|
|
|
可以看到一些有趣的 bpftrace 程序输出:
事件发生顺序:
SafepointSynchronize::begin 422373 VM Thread
RuntimeService::record_safepoint_synchronized 422373 VM Thread
LogFileOutput: 422361 VM Thread LogFileOutput::write(LogDecorations const&, char const*)
AsyncLogWriter: 422361 VM Thread AsyncLogWriter::instance()
sp vfs_call: 422361 VM Thread kprobe:vfs_write
AsyncLogWriter: 422361 VM Thread VMThread::inner_execute(VM_Operation*)
SafepointSynchronize::end 422373 VM Thread
可见 vfs_write 写文件的 syscall 调用,是同步地发生在 STW 期间的。即在 SafepointSynchronize::begin 与
SafepointSynchronize::end 之间。
一些 stack 信息:
@AsyncLogWriter[422361, 422373, VM Thread,
AsyncLogWriter::instance()+0
LogTagSet::vwrite(LogLevel::type, char const*, __va_list_tag*)+471
LogTargetHandle::print(char const*, ...)+159
LogStream::write(char const*, unsigned long)+338
outputStream::do_vsnprintf_and_write_with_automatic_buffer(char const*, __va_list_tag*, bool)+194
outputStream::print_cr(char const*, ...)+407
GCTraceTimeLoggerImpl::log_end(TimeInstant<CompositeCounterRepresentation, CompositeElapsedCounterSource>)+288
G1CollectedHeap::do_collection_pause_at_safepoint_helper(double)+2116
G1CollectedHeap::do_collection_pause_at_safepoint(double)+53
VM_G1CollectForAllocation::doit()+75
VM_Operation::evaluate()+226
VMThread::evaluate_operation(VM_Operation*)+177
VMThread::inner_execute(VM_Operation*)+436
VMThread::run()+199
Thread::call_run()+196
thread_native_entry(Thread*)+233
start_thread+755
]: 18
@LogFileOutput[422361, 422373, VM Thread,
LogFileOutput::write(LogDecorations const&, char const*)+0
LogTargetHandle::print(char const*, ...)+159
LogStream::write(char const*, unsigned long)+338
outputStream::do_vsnprintf_and_write_with_automatic_buffer(char const*, __va_list_tag*, bool)+194
outputStream::print_cr(char const*, ...)+407
GCTraceTimeLoggerImpl::log_end(TimeInstant<CompositeCounterRepresentation, CompositeElapsedCounterSource>)+288
G1CollectedHeap::do_collection_pause_at_safepoint_helper(double)+2116
G1CollectedHeap::do_collection_pause_at_safepoint(double)+53
VM_G1CollectForAllocation::doit()+75
VM_Operation::evaluate()+226
VMThread::evaluate_operation(VM_Operation*)+177
VMThread::inner_execute(VM_Operation*)+436
VMThread::run()+199
Thread::call_run()+196
thread_native_entry(Thread*)+233
start_thread+755
]: 17
@sp_begin[404917, 404924, VM Thread,
SafepointSynchronize::begin()+0
VMThread::run()+199
Thread::call_run()+196
thread_native_entry(Thread*)+233
start_thread+755
]: 1
@sp_synchronized[404917, 404924, VM Thread,
RuntimeService::record_safepoint_synchronized(long)+0
VMThread::inner_execute(VM_Operation*)+389
VMThread::run()+199
Thread::call_run()+196
thread_native_entry(Thread*)+233
start_thread+755
]: 1
你可以参见下文的 [Linux 如何模拟 IO 卡顿] 一节来模拟 GC 日志输出的目标盘 IO 卡顿、甚至挂起的情况。
如果你用 sudo dmsetup suspend /dev/$your_dm_dev 来挂起目标盘,从 Java 程序的 stdout 和 top 中可以直接看到,整个 JVM 也暂停了。
如果这时用 top -H -p $(pgrep java) 查看线程状态,你会发现一个在 D (uninterruptable_sleep) 状态的 VM Thread 线程。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
430796 labile 20 0 3068740 112820 20416 S 0.3 0.2 0:00.57 VM Periodic Tas
430779 labile 20 0 3068740 112820 20416 S 0.0 0.2 0:00.00 java
430780 labile 20 0 3068740 112820 20416 S 0.0 0.2 0:02.96 java
430781 labile 20 0 3068740 112820 20416 S 0.0 0.2 0:00.02 GC Thread#0
430782 labile 20 0 3068740 112820 20416 S 0.0 0.2 0:00.00 G1 Main Marker
430785 labile 20 0 3068740 112820 20416 S 0.0 0.2 0:00.05 G1 Service
430786 labile 20 0 3068740 112820 20416 D 0.0 0.2 0:00.04 VM Thread
如果好奇 VM Thread 挂在什么地方,可以看:
|
|
诊断 - gdb 跟踪法
由于本文的重点只是 BPF,所以 gdb 只简单写一下。
gdb debug open-jdk 的方法,你可以参见下文的 [Ubuntu 下的 jdk gdb 环境] 一节。
使用 gdb 可以在关注的 JVM 函数和内核调用中设置断点。
$ gdb -ex 'handle SIGSEGV noprint nostop pass' -p `pgrep java`
(gdb) thead thead_id_of_vm_thread
(gdb) bt
#0 __GI___libc_write (nbytes=95, buf=0x7f7cc4031390, fd=4) at ../sysdeps/unix/sysv/linux/write.c:26
#1 __GI___libc_write (fd=4, buf=0x7f7cc4031390, nbytes=95) at ../sysdeps/unix/sysv/linux/write.c:24
#2 0x00007f7cca88af6d in _IO_new_file_write (f=0x7f7cc4000c20, data=0x7f7cc4031390, n=95) at ./libio/fileops.c:1180
#3 0x00007f7cca88ca61 in new_do_write (to_do=95, data=0x7f7cc4031390 "[3598.772s][info][gc] GC(509) Pause Young (Normal) (G1 Evacuation Pause) 76M->1M(128M) 3.261ms\n", fp=0x7f7cc4000c20) at ./libio/libioP.h:947
#4 _IO_new_do_write (to_do=95, data=0x7f7cc4031390 "[3598.772s][info][gc] GC(509) Pause Young (Normal) (G1 Evacuation Pause) 76M->1M(128M) 3.261ms\n", fp=0x7f7cc4000c20) at ./libio/fileops.c:425
#5 _IO_new_do_write (fp=0x7f7cc4000c20, data=0x7f7cc4031390 "[3598.772s][info][gc] GC(509) Pause Young (Normal) (G1 Evacuation Pause) 76M->1M(128M) 3.261ms\n", to_do=95) at ./libio/fileops.c:422
#6 0x00007f7cca88a558 in _IO_new_file_sync (fp=0x7f7cc4000c20) at ./libio/fileops.c:798
#7 0x00007f7cca87f22a in __GI__IO_fflush (fp=0x7f7cc4000c20) at ./libio/libioP.h:947
#8 0x00007f7cc9eae679 in LogFileStreamOutput::flush (this=0x7f7cc4003e70) at src/hotspot/share/logging/logFileStreamOutput.cpp:93
#9 LogFileStreamOutput::write (this=this@entry=0x7f7cc4003e70, decorations=..., msg=msg@entry=0x7f7cac39b5c0 "GC(509) Pause Young (Normal) (G1 Evacuation Pause) 76M->1M(128M) 3.261ms")
at src/hotspot/share/logging/logFileStreamOutput.cpp:131
#10 0x00007f7cc9eadade in LogFileOutput::write_blocking (msg=0x7f7cac39b5c0 "GC(509) Pause Young (Normal) (G1 Evacuation Pause) 76M->1M(128M) 3.261ms", decorations=..., this=0x7f7cc4003e70)
at src/hotspot/share/logging/logFileOutput.cpp:308
#11 LogFileOutput::write (msg=0x7f7cac39b5c0 "GC(509) Pause Young (Normal) (G1 Evacuation Pause) 76M->1M(128M) 3.261ms", decorations=..., this=0x7f7cc4003e70) at src/hotspot/share/logging/logFileOutput.cpp:332
#12 LogFileOutput::write (this=0x7f7cc4003e70, decorations=..., msg=0x7f7cac39b5c0 "GC(509) Pause Young (Normal) (G1 Evacuation Pause) 76M->1M(128M) 3.261ms") at src/hotspot/share/logging/logFileOutput.cpp:320
#13 0x00007f7cc9eb3a47 in LogTagSet::log (msg=0x7f7cac39b5c0 "GC(509) Pause Young (Normal) (G1 Evacuation Pause) 76M->1M(128M) 3.261ms", level=LogLevel::Info,
this=0x7f7cca74bee0 <LogTagSetMapping<(LogTag::type)43, (LogTag::type)0, (LogTag::type)0, (LogTag::type)0, (LogTag::type)0, (LogTag::type)0>::_tagset>) at src/hotspot/share/logging/logTagSet.cpp:85
#14 LogTagSet::vwrite (this=0x7f7cca74bee0 <LogTagSetMapping<(LogTag::type)43, (LogTag::type)0, (LogTag::type)0, (LogTag::type)0, (LogTag::type)0, (LogTag::type)0>::_tagset>, level=LogLevel::Info, fmt=<optimized out>,
args=<optimized out>) at src/hotspot/share/logging/logTagSet.cpp:150
#15 0x00007f7cc9b7f09f in LogTargetHandle::print (this=this@entry=0x7f7cac39c2f0, fmt=fmt@entry=0x7f7cca41dd6e "%s") at src/hotspot/share/logging/logHandle.hpp:95
#16 0x00007f7cc9eb3232 in LogStream::write (this=0x7f7cac39c260, s=0x7f7cac39b930 " 3.261ms\n", len=9) at src/hotspot/share/logging/logStream.hpp:52
#17 0x00007f7cca03eaa2 in outputStream::do_vsnprintf_and_write_with_automatic_buffer (this=this@entry=0x7f7cac39c260, format=format@entry=0x7f7cca498e6c " %.3fms", ap=ap@entry=0x7f7cac39c158, add_cr=add_cr@entry=true)
at src/hotspot/share/utilities/ostream.cpp:131
#18 0x00007f7cca03f427 in outputStream::do_vsnprintf_and_write (add_cr=true, ap=0x7f7cac39c158, format=0x7f7cca498e6c " %.3fms", this=0x7f7cac39c260) at src/hotspot/share/utilities/ostream.cpp:144
#19 outputStream::print_cr (this=this@entry=0x7f7cac39c260, format=format@entry=0x7f7cca498e6c " %.3fms") at src/hotspot/share/utilities/ostream.cpp:158
#20 0x00007f7cc9b8fec0 in GCTraceTimeLoggerImpl::log_end (this=<optimized out>, end=...) at src/hotspot/share/gc/shared/gcTraceTime.cpp:70
#21 0x00007f7cc9afc8c4 in GCTraceTimeDriver::at_end (end=..., cb=<optimized out>, this=0x7f7cac39c688) at src/hotspot/share/gc/shared/gcTraceTime.inline.hpp:78
#22 GCTraceTimeDriver::~GCTraceTimeDriver (this=0x7f7cac39c688, __in_chrg=<optimized out>) at src/hotspot/share/gc/shared/gcTraceTime.inline.hpp:61
#23 GCTraceTimeImpl::~GCTraceTimeImpl (this=0x7f7cac39c618, __in_chrg=<optimized out>) at src/hotspot/share/gc/shared/gcTraceTime.hpp:141
#24 GCTraceTimeWrapper<(LogLevel::type)3, (LogTag::type)43, (LogTag::type)0, (LogTag::type)0, (LogTag::type)0, (LogTag::type)0, (LogTag::type)0>::~GCTraceTimeWrapper (this=0x7f7cac39c610, __in_chrg=<optimized out>)
at src/hotspot/share/gc/shared/gcTraceTime.inline.hpp:184
#25 G1CollectedHeap::do_collection_pause_at_safepoint_helper (this=this@entry=0x7f7cc4026ef0, target_pause_time_ms=target_pause_time_ms@entry=200) at src/hotspot/share/gc/g1/g1CollectedHeap.cpp:3071
#26 0x00007f7cc9afcb45 in G1CollectedHeap::do_collection_pause_at_safepoint (this=this@entry=0x7f7cc4026ef0, target_pause_time_ms=200) at src/hotspot/share/gc/g1/g1CollectedHeap.cpp:2887
#27 0x00007f7cc9b7902b in VM_G1CollectForAllocation::doit (this=0x7f7cc8ffe690) at src/hotspot/share/gc/g1/g1VMOperations.cpp:146
#28 0x00007f7cca35b632 in VM_Operation::evaluate (this=this@entry=0x7f7cc8ffe690) at src/hotspot/share/runtime/vmOperations.cpp:70
#29 0x00007f7cca35ced1 in VMThread::evaluate_operation (this=this@entry=0x7f7cc40e0f10, op=0x7f7cc8ffe690) at src/hotspot/share/runtime/vmThread.cpp:269
#30 0x00007f7cca35d2d4 in VMThread::inner_execute (this=this@entry=0x7f7cc40e0f10, op=<optimized out>) at src/hotspot/share/runtime/vmThread.cpp:415
#31 0x00007f7cca35d5c7 in VMThread::loop (this=0x7f7cc40e0f10) at src/hotspot/share/runtime/vmThread.cpp:482
#32 VMThread::run (this=0x7f7cc40e0f10) at src/hotspot/share/runtime/vmThread.cpp:162
#33 0x00007f7cca2d7834 in Thread::call_run (this=0x7f7cc40e0f10) at src/hotspot/share/runtime/thread.cpp:394
#34 0x00007f7cca0326c9 in thread_native_entry (thread=0x7f7cc40e0f10) at src/hotspot/os/linux/os_linux.cpp:724
#35 0x00007f7cca894b43 in start_thread (arg=<optimized out>) at ./nptl/pthread_create.c:442
#36 0x00007f7cca926a00 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81
云原生下可能加剧的问题
-
worker node 共享内存 或 container limit 内存后,Direct Page Reclaim
在云环境下,一台机器可能运行很多 container 。有的 container 是高 IO 的应用,如写日志,这些都会占用 page cache 和对共享的 disk 产生争用压力 。 整机的内存不足,或者是 container 本身的内存不足,都可能触发 Direct Page Reclaim
-
worker node 共享本地磁盘 IO 争用
-
Ceph 等 PV 网络盘稳定性远不如本地盘,带宽与 latency 相对不稳定。
如以下一个配置,多个 container 可能共享了 emptyDir 用的本地盘。然后在 IO 争用时,写 GC 日志就可能出现 STW 下的高 latency ,直接导致服务 API latency 超时。
|
|
结语
资金是好东西,注意力也是好东西,人们为了拥有它们无所不用其极。但也有它的副作用。君不见现在 IT 技术界,很容易就出现一些 拜名主义,时常三句不离一堆新技术 keyword 。知道锤子好是好事,但不是所有东西都是钉子。了解东西本身和它的特性与缺点,才是做好技术选型的关键。现在市场上已经开始了一些 BPF 的滥用,我们静观其变吧。我还是觉得, eBPF 现在最成熟的应用场景是:用其它手段难以分析的问题的跟踪。如内核的异常行为。
后面,我会写另外两编 Twins 文章:《eBPF 求证坊间传闻:mmap + Java Safepoint 可导致整个 JVM 服务卡顿?》、《如何测量 进程级别的 IO 延迟》
“學而不思則罔 思而不學則殆” – 《论语·为政》
附录
Linux 应用的写文件操作为何会卡顿
了解过 Linux IO 机制的同学可能会提出疑问,应用的 write syscall 是写入 pagecache(dirty),然后再由专门的 pdflush 线程负责实际的IO操作。所以应用本身一般是不会有写文件卡顿的情况的。除非应用自己调用 fsync() 强制同步落盘。
的确,Linux 的主要IO写路径(Wite Path)是异步为主。但凡事有例外(魔鬼在细节),这正是程序员世界好玩的地方:Why buffered writes are sometimes stalled - YOSHINORI MATSUNOBU 。这文章总结起来有几个可能
- READ MODIFY WRITE - 一些情况需要先读再写
- WRITE() MAY BE BLOCKED FOR “STABLE PAGE WRITES” - 写入的 page 之前已经是 dirty 状态,且正在被 pdflush writeback 线程锁住,准备落盘。
- WAITING FOR JOURNAL BLOCK ALLOCATION IN EXT3/4
上面完整了吗?我看还有其它可能:
- Direct Page Reclaim - 内存页回收
当应用向内核申请内存,而内核发现当前的空闲内存(如果是 container(cgroup),空闲内存只包括 limit 内的部分)不足以满足时, 就可能会挂起当前线程,去释放更多的内存,通常这个操作包括:
- 之前标记为 dirty 的 page cache 的落盘,落盘当然是慢的 IO 操作了。当前线程可能进入 “uninterruptable_sleep” 状态。直到 IO 写和释放内存完成。
在云环境下,一台机器可能运行很多 container 。有的 container 是高 IO 的应用,如写日志,这些都会占用 page cache 和对共享的 disk 产生争用压力 。 整机的内存不足,或者是 container 本身的内存不足,都可能触发 Direct Page Reclaim 。
更多可参考:Our lessons on Linux writeback: do “dirty” jobs the right way
偶像 brendangregg 利用 BPF(bpftrace) 有诊断方法:vmscan.bt
Linux 如何模拟 IO 卡顿
网上能搜索到的模拟 IO 卡顿大概有两个方法:
- device mapper delay 法
- systemtap 注入延迟法
本文用的是 device mapper delay 法。device 本身带了一个 delay。
|
|
另外如果 debug 需要,可以挂起 device ,直接让 mapper device 的所有 IO 操作进程挂起(uninterruptable_sleep):
|
|
Ubuntu 下的 BPF 跟踪堆栈由于 -fno-omit-frame-pointer 的 glibc 缺失的问题
sudo apt install libc6-prof
env LD_LIBRARY_PATH=/lib/libc6-prof/x86_64-linux-gnu /usr/lib/jvm/java-17-openjdk-amd64/bin/java ...
TL;DR :
https://bugs.launchpad.net/ubuntu/+source/glibc/+bug/1908307
Ubuntu 下的 jdk gdb 环境
gdb 用的 symbol table
|
|
Ubuntu 定制的 openjdk 源码:
详细见:https://www.cyberciti.biz/faq/how-to-get-source-code-of-package-using-the-apt-command-on-debian-or-ubuntu/
|
|