The so-called Sidecarless of Istio Ambient is, strictly speaking, a change from a sidecar container of pod to a sidecar pod of pods on a worker node. Note that I’m introducing the term sidecar pod here. To implement pods on the same worker node share a sidecar pod, you need to solve the problem of redirecting traffic from all pods to the sidecar pod.
The solution to this problem has gone through two versions during the development of Istio Ambient.
- redirecting pod traffic to the
sidecar podvia the worker node - have the
sidecar pod“join” each pod’s network namespace, and redirect traffic to thesidecar podwithin the network namespace (pod traffic does not need to be routed through a worker node).
The Istio Ambient project team has explained the reason for this change in Istio Ambient at a relatively high level:
The official Istio Ambient documentation also describes the latest implementation:
In this article, I try to deep dive into the implementation of the traffic environment setup process and the related background technologies from the low level. To record my curiosity. I also hope to satisfy the curiosity of a small number of readers.
kernel fundamentals
The section “kernel fundamentals” has a lot of background on TL;DR, which I found to be a bit of a brain fart when I wrote this article. If you just want to know the results, skip straight to the " Istio Ambient’s Curiosities" section.
network namespace basics
From Few notes about network namespaces in Linux :
Kernel API for NETNS
Kernel offers two system calls that allow management of network namespaces.
The first one is for creating a new network namespace, unshare(2). The first approach is for the process that created new network namespace to fork other processes and each forked process would share and inherit the parent’s process network namespace. The same is true if exec is used.
The second system call kernel offers is setns(int fd, int nstype). To use this system call you have to have a
file descriptorthat is somehow related to the network namespace you want to use. There are two approaches how to obtain the file descriptor.The first approach is to know the process that lives currently in the required network namespace. Let’s say that the PID of the given process is $PID. So, to obtain file descriptor you should open the file
/proc/$PID/ns/netfile and that’s it, pass file descriptor tosetns(2)system call to switch network namespace. This approach always works.Also, to note is that network namespace is per-thread setting, meaning if you set certain network namespace in one thread, this won’t have any impact on other threads in the process.
Notice: from the documentation of setns(int fd, int nstype):
The setns() system call allows the calling thread to move into different namespaces
Note that it is thead, not the entire process. This is very, very important!
The second approach works only for iproute2 compatible tools. Namely,
ipcommand when creating new network namespace creates a file in /var/run/netns directory and bind mounts new network namespace to this file. So, if you know a name of network namespace you want to access (let’s say the name is NAME), to obtain file descriptor you just need to open(2) related file, i.e. /var/run/netns/NAME.Note that there is no system call that would allow you to remove some existing network namespace. Each network namespace exists as long as there is at least one process that uses it, or there is a mount point.
Having said so much above, the key point I want to quote in this article is that setns(int fd, int nstype) can switch the
current network namespace of the threadfor the calling thread 。Socket API behavior
First, each socket handle you create is bound to whatever network namespace was active at the time the socket was created. That means that you can set one network namespace to be active (say NS1) create socket and then immediately set another network namespace to be active (NS2). The socket created is bound to NS1 no matter which network namespace is active and socket can be used normally. In other words, when doing some operation with the socket (let’s say bind, connect, anything) you don’t need to activate socket’s own network namespace before that!
Having said so much above, the main point I want to quote in those articles is that a socket actually binding to a network namespace. This binding occurs when the socket is created, and it is not changed by the current network namespace of the creator thread.
If you don’t know much about network namespace, you can take a look at:
Use Unix Domain Sockets to transfer File Descriptor between processes
Use Unix Domain Sockets to transfer File Descriptor between processes:File Descriptor Transfer over Unix Domain Sockets
New method for new kernel (5.6 and above): Seamless file descriptor transfer between processes with pidfd and pidfd_getfd
Some references:
Network namespace magic of Istio Ambient
Finally, about the trick way Istio Ambient puts it all together.
Ztunnel Lifecyle On Kubernetes describe the high level design:
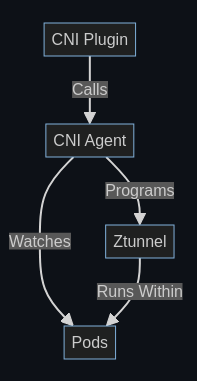
The CNI Plugin is a binary installed as a CNI plugin on the node. The container runtime is responsible for invoking this when a Pod is being started (before the containers run). When this occurs, the plugin will call out to the CNI Agent to program the network. This includes setting up networking rules within both the pod network namespace and the host network. For more information on the rules, see the CNI README. This is done by an HTTP server running on
/var/run/istio-cni/pluginevent.sock.An alternative flow is when a pod is enrolled into ambient mode after it starts up. In this case, the CNI Agent is watching for Pod events from the API server directly and performing the same setup. Note this is done while the Pod is running, unlike the CNI plugin flow which occurs before the Pod starts.
Once the network is configured, the CNI Agent will signal to Ztunnel to start running within the Pod. This is done by the ZDS API. This will send some identifying information about the Pod to Ztunnel, and, importantly, the Pod’s network namespace file descriptor.
Ztunnel will use this to enter the Pod network namespace and start various listeners (inbound, outbound, etc).
Note:
While Ztunnel runs as a single shared binary on the node, each individual pod gets its own unique set of listeners within its own network namespace.

Istio CNI & Istio ztunnel sync pod network namespace high level
{kind=link}
The diagram already contains a lot of information. I won’t write much comment. :)
Here are some implementation details:

Istio CNI & Istio ztunnel sync pod network namespace
{kind=link}
The diagram already contains a lot of information. I won’t write much comment. :)
Encapsulation in ztunnel
|
|
InPodSocketFactory::run_in_ns(…)
|
|
Reference:
|
|
|
|
If you are curious about what listeners ztunnel has, you can see: ztunnel Architecture
Istio CNI
|
|
See:
- Istio CNI Node Agent
- Source code analysis: What happens behind the scenes when K8s creates pods (V) (2021)
- Experiments with container networking: Part 1
End words
Is it over engineering? I don’t have an answer to this question. The so-called over engineering is mostly an evaluation after the fact. If you succeed and the software has a great influence, it is called “it is a feature not a bug”. Otherwise, it is called “it is a bug not a feature”.
Overengineering (or over-engineering) is the act of designing a product or providing a solution to a problem that is complicated in a way that provides no value or could have been designed to be simpler.
– [Overengineering - Wikipedia](https://en.wikipedia.org/wiki/Overengineering#:~:text=Overengineering (or over-engineering),been designed to be simpler.)