所谓 Sidecarless 的 Istio Ambient ,严格来说,是由 sidecar container of pod 变成 sidecar pod of pods on a worker node。注意,这里我引入一个词:sidecar pod 。 要实现同一 worker node 上的 pod 共享一个 sidecar pod,就要解决把所有 pod 的流量导向到 sidecar pod 的问题。
这个问题的解决方案,在 Istio Ambient 开发过程中经历两个版本:
- 把 pod 流量经由 worker node 重定向到
sidecar pod - 让
sidecar pod“加入” 到每一个 pod 的 network namespace。流量在 network namespace 内重定向到sidecar pod(pod 流量不需要经由 worker node)
Istio Ambient 的项目组在比较 high level 说明过 Istio Ambient 这个变化的原因:
Istio Ambient 官方文档也有说明最新的实现:
本文尝试从 low level 补充说明一下这个流量环境的 setup 过程实现细节和相关的背景技术。以记录我的好奇心。也希望能满足小部分读者的好奇心。
kernel 基本原理
“kernel 基本原理” 这节有太多 TL;DR 的背景知识,因这我写这篇文章时,发觉要说明白这个主题的确有点烧脑。如果你只想知道结果,请直接跳到 “ Istio Ambient 的奇技*巧” 部分。
network namespace 基本原理
Few notes about network namespaces in Linux 一文中说了:
Kernel API for NETNS
Kernel offers two system calls that allow management of network namespaces.
The first one is for creating a new network namespace, unshare(2). The first approach is for the process that created new network namespace to fork other processes and each forked process would share and inherit the parent’s process network namespace. The same is true if exec is used.
The second system call kernel offers is setns(int fd, int nstype). To use this system call you have to have a
file descriptorthat is somehow related to the network namespace you want to use. There are two approaches how to obtain the file descriptor.The first approach is to know the process that lives currently in the required network namespace. Let’s say that the PID of the given process is $PID. So, to obtain file descriptor you should open the file
/proc/$PID/ns/netfile and that’s it, pass file descriptor tosetns(2)system call to switch network namespace. This approach always works.Also, to note is that network namespace is per-thread setting, meaning if you set certain network namespace in one thread, this won’t have any impact on other threads in the process.
注意:setns(int fd, int nstype) 中也说了:
The setns() system call allows the calling thread to move into different namespaces
注意是 thead(线程),不是整个 process(进程)。这点非常非常重要!
The second approach works only for iproute2 compatible tools. Namely,
ipcommand when creating new network namespace creates a file in /var/run/netns directory and bind mounts new network namespace to this file. So, if you know a name of network namespace you want to access (let’s say the name is NAME), to obtain file descriptor you just need to open(2) related file, i.e. /var/run/netns/NAME.Note that there is no system call that would allow you to remove some existing network namespace. Each network namespace exists as long as there is at least one process that uses it, or there is a mount point.
上面说了那么多,本文想引用的重点是 setns(int fd, int nstype) 可以为调用的线程切换
线程的当前 network namespace。Socket API behavior
First, each socket handle you create is bound to whatever network namespace was active at the time the socket was created. That means that you can set one network namespace to be active (say NS1) create socket and then immediately set another network namespace to be active (NS2). The socket created is bound to NS1 no matter which network namespace is active and socket can be used normally. In other words, when doing some operation with the socket (let’s say bind, connect, anything) you don’t need to activate socket’s own network namespace before that!
上面说了那么多,本文想引用的重点是 socket 其实有自己绑定的 network namespace,这个绑定发生在 socket 被创建时,它不由创建者线程的当前 network namespace 的改变而改变。
如果你对 network namespace 了解不多,可以看看:
用 Unix Domain Sockets 在进程间传递 File Descriptor
使用 Unix Domain Sockets 可以在进程间传递 File Descriptor :File Descriptor Transfer over Unix Domain Sockets
新 kernel (5.6以上)的新方法 : Seamless file descriptor transfer between processes with pidfd and pidfd_getfd
一些参考:
Istio Ambient 的奇技*巧
前面说了那么多铺垫,现在终于开始说 Istio Ambient 的 put it all together 的奇技*巧了。注意,这里的 “奇技*巧” 用作褒义词。
Ztunnel Lifecyle On Kubernetes 中说了 high level 的设计:
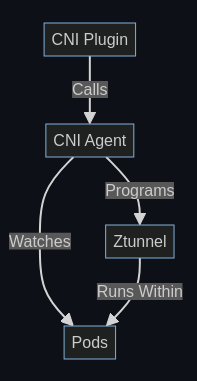
The CNI Plugin is a binary installed as a CNI plugin on the node. The container runtime is responsible for invoking this when a Pod is being started (before the containers run). When this occurs, the plugin will call out to the CNI Agent to program the network. This includes setting up networking rules within both the pod network namespace and the host network. For more information on the rules, see the CNI README. This is done by an HTTP server running on
/var/run/istio-cni/pluginevent.sock.An alternative flow is when a pod is enrolled into ambient mode after it starts up. In this case, the CNI Agent is watching for Pod events from the API server directly and performing the same setup. Note this is done while the Pod is running, unlike the CNI plugin flow which occurs before the Pod starts.
Once the network is configured, the CNI Agent will signal to Ztunnel to start running within the Pod. This is done by the ZDS API. This will send some identifying information about the Pod to Ztunnel, and, importantly, the Pod’s network namespace file descriptor.
Ztunnel will use this to enter the Pod network namespace and start various listeners (inbound, outbound, etc).
Note:
While Ztunnel runs as a single shared binary on the node, each individual pod gets its own unique set of listeners within its own network namespace.

Istio CNI & Istio ztunnel sync pod network namespace high level
{kind=link}
图中已经较大信息量了,这个博客的旧读者也知道,我不会写太多文字说明了 :)
下面是一些实现细节:

Istio CNI & Istio ztunnel sync pod network namespace
{kind=link}
图中已经较大信息量了,这个博客的旧读者也知道,我不会写太多文字说明了 :)
ztunnel 的封装
|
|
InPodSocketFactory::run_in_ns(…)
|
|
参见:
|
|
|
|
如果你好奇 ztunnel 有哪些 listener ,可以看: ztunnel Architecture
Istio CNI
|
|
参见:
- Istio CNI Node Agent
- 源码解析:K8s 创建 pod 时,背后发生了什么(五)(2021)
- Experiments with container networking: Part 1
结语
“奇技*巧” over engineering 了吗?这个问题,我没的答案。所谓的 over engineering ,大部分是事后诸葛亮的评价。如果你成事了,软件影响力大了,就叫 it is a feature not a bug,否则,就叫: it is a bug not a feature.
Overengineering (or over-engineering) is the act of designing a product or providing a solution to a problem that is complicated in a way that provides no value or could have been designed to be simpler.
– [Overengineering - Wikipedia](https://en.wikipedia.org/wiki/Overengineering#:~:text=Overengineering (or over-engineering),been designed to be simpler.)