Hello everybody。这是一系列记述中年危机码农,打算从零开始学习和实践构建 LLM/AI 的故事。他可能学有所成,也可能会半途而废。不管如何,把故事记述下来。像曹雪芹的《石頭記》,叙述了青春的绽放,同时也道出了乾坤的循环:
![]()
系列开篇
系列初衷
大概在我 35 岁之前。我一直认为自己是专业技能上比较有天赋的那类人。专业上懂的东西比大部分人深,也比大部分人广。对于新知识的学习,我也总可以比别个快地找到资料和门路。那时候,觉得自己是个 10x developer :
A 10x developer is a software engineer who is 10 times more productive than other developers with a similar level of expertise. They are known for writing better code, completing more tasks, and working more efficiently than their peers.
35 岁后,由于各种现实的杂音,自觉在某些工作上开始了这个 “服务降级(Service degradation)” 过程:
10x developer -> 5x -> 1x -> 0.5x -> 0.2x ….
对于中年码农,要面对这个现实并不是一件容易的事。一开始,甚至会因比不上年轻人而产生各位羡慕嫉妒恨的笑话。想想也好笑,当年的职场长者这么对待我时,我还以为不公,现在怎么自己也产生了这个当年鄙视的念头?这又好比年轻人对炒楼者把楼价炒上天很不滿,但当自己上车变成中年时,恨不得把楼价炒上天……扯远了,回到主题吧。
落后了,就要分析一下原因:
-
变笨了吗?☺️ NO
-
知识变难了吗?☺️ NO
-
获取知识和学习过程变难了吗? ☺️ NO
-
持之以恒努力了吗? 😭 Maybe…not?
-
注意力能长时间集中吗?😭 NO…
有什么方法让自己坚持和集中注意力?不如把学习内容和过程记录下来,同时可以分享,如果能帮到其它人,就更好了。
入门书
我是 AI/LLM 小白,但习惯了学习新知识先从主流信息入门。《Build a Large Language Model (From Scratch)》 —— SEBASTIAN RASCHKA 是本近期刚出版的,口碑不错的 LLM 图书。书写得事无巨细,有时真有点罗嗦,不过,也看出作者是认真写作的。不像一些冲热点打一炮就跑路的。
我无意写读书笔记。事实上,单纯的读书笔记分享的作用也有限。因为每个读者的知识背景,学习方式不同。我假设读者已经有这本书。本系列脱离原书而看,是没多大意义的。但如果读者在看书时遇到问题,或者找不到方向,可以阅读本系列,看看是否有帮助。
中文原生程序员学 AI 的痛
不打算从头到尾顺序写《Build a Large Language Model (From Scratch)》这本书的学习过程。我只会跳跃着记录一些我认为 与我一样属于中文原生程序员 的人,最可能在学习 LLM 过程中转不过弯,甚至入坑的问题。算是共性问题吧。或者直接点说,是我尝试记录一个过程:以中文程序员的思维为起点,去构建一个 LLM 要理解什么,学习什么。一般,有以下类型难点:
- 英文术语,单词背后真实意味的领会。
- 数学公式,离开学校已经多年,很多日常编程工作应用不上的东西已经还给老师了。
- 书中有的内容对程序员来说,是基本功,可以跳过。
Chapter 1. 介绍 Large Language Models(LLM)
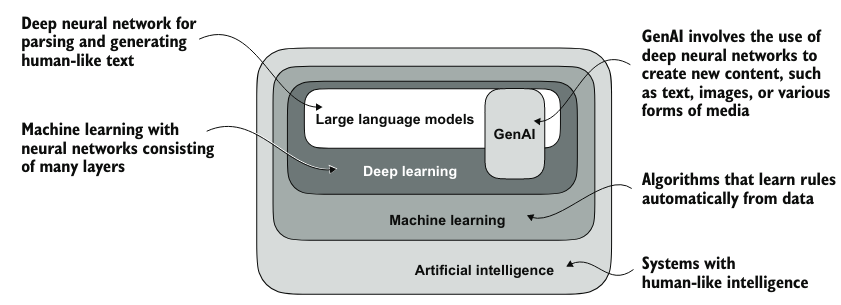
图:AI 到 LLM 之间各种技术的关系
这个图没什么意外,符合之前的认知,不多说了。
1.4 介绍 transformer 的架构
大多数现代 LLM 都依赖于 Transformer 架构,这是 2017 年论文 Attention Is All You Need 中提出的深度神经网络(deep neural network architecture)架构。要理解 LLM,我们必须了解最初的 transformer,它是为机器翻译而开发的,将英文文本翻译成德语和法语。下图 描绘了 transformer 架构的简化版本。
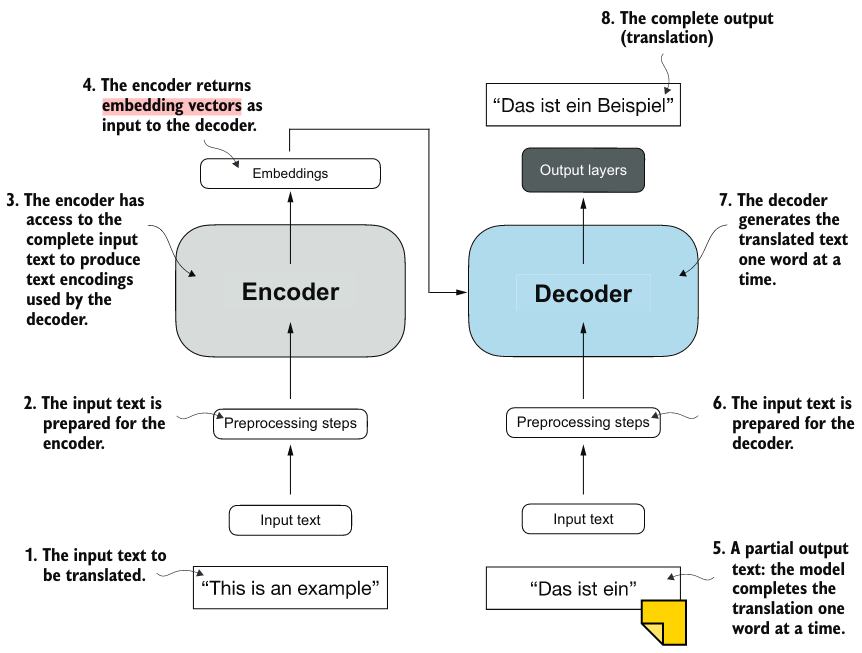
图:Transformer 机器翻译架构简图
图中可见由两个主模块组成:Encoder 与 Decoder 。Encoder 把源文本转为向量(vector),Decoder 负责把这些 vector 转为目标语言。Encoder 与 Decoder 内部均由很多由 self-attention 机制连接的层合成。这种机制让模型可以提取出顺序输入数据中的上下文联系,从而输出上下文相关的内容。
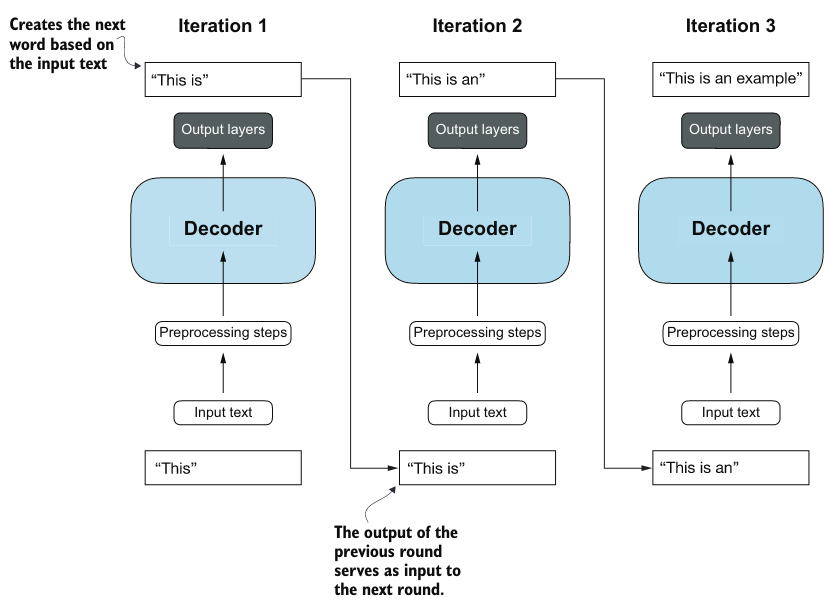
上图是一个有状态的 Decoder。它每次执行只输出一个词。上图 Decoder 的输入是 “This is an example” 的 embedding vectors。 Decoder 的状态是已经翻译到 “Das ist ein” 了,Decoder 在思考下一个词。
与原始 Transformer 架构相比,普通的 GPT 架构相对简单。本质上,它只有 Decoder 部分,没有 Encoder。由于像 GPT 这样的 decoder-style 模型通过一次预测一个单词来生成文本,因此它们被视为一种自回归模型(autoregressive model)。自回归模型将其先前的输出作为未来预测的输入。因此,在 GPT 中,每个新单词都是根据其之前的序列来选择的,这提高了生成文本的连贯性。