
概述
Dave Farley 否定了 “氛围编程(Vibe Coding)” 概念,强调编程核心在于问题理解与精确表达,指出 AI 编程面临规格、验证与演进三大难题,软件工程仍在进化而非消亡。
译者引
本文翻译自 Dave Farley 的 Vibe Coding Is The WORST IDEA Of 2025 。 国内的朋友可能不太熟识 Dave Farley。 他凭借 LMAX Disruptor 荣获杜克大学开源软件奖,并因其在软件工程领域的贡献被评为 ACM 杰出工程师。Dave 是《持续交付》和《软件交付的原则与实践》的合著者。 LMAX Disruptor 是一种高性能的并发编程框架/数据结构,最初由英国金融交易所 LMAX (London Multi Asset Exchange) 团队在 2010 年左右开源。它的目标是解决 在极高吞吐量、低延迟场景下的多线程消息传递问题,主要应用于 金融交易系统、实时计算、事件驱动系统等。它的设计思路更多的是 利用现代 CPU 架构(缓存、内存屏障)来优化并发性能,而不仅仅是“一个快的队列”。很多框架(如 Log4j2、Chronicle Queue)都借鉴了 Disruptor 的思想。
其实业界的几位知名老程序员,都对 AI 编程甚至是 AI 技术本身的过热提出过不同意见:如 Java 之父 James Gosling 认为:“AI”与“Machine Learning”只是高级统计方法。
而怎么看这些意见,是预置立场地认为,新技术让老程序员的旧技术严重贬值,甚至失掉饭碗,吃不到的葡萄是酸的,所以老程序员反对,还是从他们的观点中看到一条理性的回归出路?有人认为,就像当初汽车技术未成熟、维护成本极高时,人们判断汽车永远代替不了马车。所以,人们总是短视地只以当前状态来判断技术方向。
对此,我还没有自己的见解。由于 AI 翻译与本人复核的能力有限,翻译错漏难免,还请谅解。
引言:“Vibe Coding” 的诞生
在今年 2 月 2 日,Andrej Karpathy——OpenAI 的创始人之一、前特斯拉 AI 负责人,提出了一个新的术语,用来描述与 AI 助手一起编程的一种风格。他称之为 氛围编程(Vibe Coding)。我对 “TL;DR(太长不看)” 和 “语义扩散(semantic diffusion)” 这些概念并不陌生,但我觉得这次可能刷新了纪录。
对推文的误解
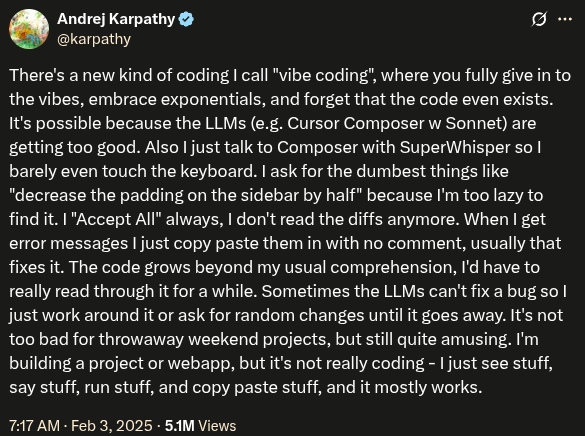
这是一条长达一千字符的推文,但似乎很少有人读到后半段。Andrej 在推文的前 300 个字符左右解释了他所谓的氛围编程,其余部分则描述了这种“幼稚玩具小镇式编程方法”可能带来的一些后果。
我个人并不认识 Andrej,所以无法确切知道他发这条推文的真实意图。但读起来我觉得更像是 讽刺。在推文的末尾,他写道:
“把周末的小项目丢掉倒也没什么大不了的,但那不是真正的编程。我只是看到一些东西、运行一些东西、复制再运行一些东西,大多数时候还能凑合用。”
所以我觉得氛围编程至少可以角逐一下年度最糟糕创意奖。
然而,这条推文却火了,现在已经成为我们领域内广为人知的一个词汇。而这就是我们今天要讨论的话题。
Vibe Coding 诱人却有缺陷
大家好,我是 Dave Farley,欢迎来到我的软件工程频道。能与大型语言模型进行轻松对话并最终得到一个可运行的系统,这个想法既令人印象深刻又很有吸引力。但在我看来,它几乎完全忽略了编程的真正本质。
软件开发的真正难点
这让我们回到软件行业的一个顽疾——“写代码就是最难的部分”。非技术人员相信这一点,因为代码在他们眼里复杂又神秘。开发者也相信这一点,因为代码让他们感到舒适和珍贵,能清晰地定义他们的技能,并把他们与那些不会写代码的“没那么聪明”的人区分开来。
于是我们建立了一整套以此为基础的招聘体系:
优秀程序员的标志就是他掌握了哪些编程语言和框架。很多人甚至用工具来定义自己的工作身份:“我是 Java 程序员”“我是 Web 开发者”等等。
我曾经坦言,我雇过一些程序员,他们不会用我们当时项目里所用的技术,但我从未为此后悔过。我的经验是,如果一个人真正擅长编程,那么学会一门语言只需要几天,也许一两周就够了。
做好软件开发是非常困难的,但难点并不在于编程语言。让我们回到 Andrej 的推文。如果我们完全沉浸在“氛围”里,甚至忘记代码的存在,会怎样?另一群经常这样做的人就是非技术人员,他们只是想用电脑完成某些事。到目前为止,我们人类程序员一直扮演着“编程助手”的角色,把他们的需求翻译成能运行的东西。那效果如何呢?在我看来,通常并不好。尤其对于规模大或复杂的软件,几乎都会以失败收场。而目前,人类在这方面仍然比机器更聪明。
简化编程的幻象
这并不是因为把需求翻译成编程语言很难,而是因为 要把问题精炼为计算机能够执行的精确、确定性的指令本身就极其困难——无论有没有 LLM,计算机最终还是这样运作的。
编程对精确性的持久需求
如果你比较几十年前的程序和今天的程序,会发现一个奇怪的现象:为了让程序能运行,我们所需表达的细节程度几乎一直保持一致,这已经持续了数十年。无论用什么方式去编码,这个细节层次几乎没有变。
编程语言并不是因为某些“潮流”或程序员的“受虐倾向”而变得奇怪,而是作为工具逐步进化出来的,目的就是 清晰、准确地表达一个想法,并以所需的精确度来驱动现代计算机中数十亿个开关组成的机器。
事实上,编程语言比人类语言要简单得多——更受限制,也更精确。这恰恰是优势,因为它帮助我们把问题分解成实现目标所需的步骤。编程语言的设计目的就是 帮助我们组织思维、分解问题,从而构建出能达成预期结果的系统。
自然语言编程的谬误
所以,认为用模糊不精确的人类语言能更好地定义计算机行为,这在我看来完全偏离了真相。氛围编程根本不是正确答案。
人类试图用自然语言追求清晰和精确的另一个例子是法律。如果你读过任何法律文件,就会同意它们并不是我们所期望的那种“清晰和精确”。
我们当然可以从很多角度来理解编程行为。大多数人可能会说:编程就是用编程语言写代码。但我对这种看法持怀疑态度。这就好比把“水管工”定义为“会用扳手的人”。
超越写代码:编程的三大目标
编程远不止于此。语法和代码结构之外的东西才是编程中更有趣、更复杂的部分。我们用代码“绘制”的图景,以及通过代码实现的结果,比代码本身更有价值。
我认为编程语言的三大核心目标是:
- 帮助我们组织对问题的思考;
- 帮助我们把理解传达给其他人类;
- 告诉计算机我们希望它执行什么。
这三者在编程中都至关重要。最难的部分往往是:能否在足够细节层面上理解问题,从而确保我们的解决方案确实有效。
编程语言提供了很多工具,帮助我们约束思维,把问题拆分为可管理的部分:模块化、内聚性、关注点分离、抽象、受控耦合等等。这些思维方式既来自语言的语法构造,也来自我们长期积累的设计经验。
软件设计中的“品味”问题
程序员(包括大型语言模型)都必须学会在设计中应用“良好品味”,以便有效利用这些语言构造。但现实是,我们见过太多反例,说明并非所有人都能做到。
更糟的是,大模型的训练数据里既有好代码,也有大量糟糕的、丑陋的代码,而“坏的”往往比“好的”更多。而我们这个行业也没能很好地定义什么才算“好代码”。问十个程序员什么是好代码,可能会得到十五个不同的答案。
这意味着大模型很可能缺乏判断“好代码”的能力。除非我们明确告诉它,否则它很可能生成糟糕的代码。更麻烦的是,什么是好代码往往取决于上下文。一个场景里的优秀方案,在另一个场景可能过于简单或过度设计。
我个人的经验让我倾向于一种防御性的、渐进式的设计与开发方式:假设我们最初的猜测大概率是错的,因此必须保持能在发现问题时及时修正的能力。
衡量质量的唯一标准:可修改性
我相信,衡量代码质量的唯一有意义的标准就是它的可修改性。
因此,我总是追求最简单、最易读、最容易修改的解决方案。
但这在大模型编程下意味着什么呢?如果 AI 每次改动时几乎都会从零重写所有代码,那是不是所有代码都一样容易修改?答案是否定的。
代码只有在我们能确认改动后它依旧符合预期时,才算易于修改。但这种确认需要 精确的系统规格说明。对于人类来说,很多“系统应该做什么”只是隐含的,并没有写进代码里。可对 AI 生成代码而言,这就是更大的问题。
AI 编程揭示的三大难题
AI 在编程中的应用,凸显了三个重大问题:
- 我们如何用足够精确的方式表达我们的需求?
- 我们如何验证最终结果符合需求?
- 我们如何保持能以小步快跑、可控渐进的方式推进?
第一个问题暴露了自然语言的模糊性。第二个问题强调了 自动化测试 在 AI 编程中的重要性。第三个问题则指出 机器写代码的方式与人类截然不同,尤其在可重现性方面差距巨大。
所有成功的系统都是随着时间演进的,这要求我们能够在环境或理解发生变化时修改它。人类构建复杂系统的秘诀就是 分区隔离,保证在一个部分的改动不会扩散到其他部分。这在物理工程和软件工程里都是共通规律。
因此,我提出的“代码质量取决于它的可修改性”非常重要。这也是为什么 持续集成(CI)与持续交付(CD) 对复杂软件如此关键,而这与是否使用 AI 写代码无关。
问题在于,AI 通常在每次改动时从头生成代码。忽视“回头修改”的重要性,正是此前所有提升抽象层次的尝试失败的原因——从 90 年代的 4GL 和模型驱动开发,到低代码、无代码平台,都假设“代码一次就对”,不需要后续修正。
人类 vs. 机器的代码修改方式
如果作为人类程序员的我,构建了一个复杂到无法完全记住细节的系统,现在想在不破坏它的前提下做个小改动,我有两种方法:
- 写完整的测试,并在修改后全部回归测试;
- 把系统设计成局部改动不会影响整体。
但第二种方法依赖于一个前提:编译器和语言的确定性。也就是说,我能相信未改动的代码依然会像上次那样执行。AI 能做到这一点吗?不一定。
如果 AI 每次改动都重写全部代码,或者偶尔重写,甚至因为学习到新模式而改变理解方式,我就无法再信任它能重现之前的正确结果。于是,我必须检查它的行为。这使得自动化测试、CI/CD 对 AI 生成代码的必要性,比对人类代码更高。
自动化测试的关键作用
最近我看到一位 OpenAI 研究员的视频: Prompt Engineering is Dead, Every Thing is a Spec ,他也强调了同一点:对 AI 最好的提示就是“可执行的规格说明”。
也就是说,我们需要用精确的、可复现的示例来描述系统应有的行为。这样既能明确需求,也能验证结果。编程的重心因此从“实现细节”转向“更精确地定义系统意图”。
结论:软件工程不是消亡,而是进化
因此,氛围编程并没有解决这些问题,它远远不够。软件工程并没有消亡,而是在演变。
我认为,这三个问题是代码本质中不可回避的挑战,不管代码是人写的还是 AI 写的。任何下一代编程方式,若不能解决这三点,最终都注定行不通。
![]()
配图
配图摄于我于 2025年8月底的一次深圳桔钓沙之行。在沙滩上偶遇有人写了 4 个字,估计是暑假快结束了,学生喝多了提了字。我心中有感,于是班門弄斧,略作修改。